
Что такое ИСПОЛИН
ИСПОЛИН — B2B-платформа для SEO-агентств и in-house маркетинговых команд. Внутри шесть модулей: семантика, контент-пайплайн, аналитика трафика и позиций, GEO-аудит, мониторинг видимости в AI-движках и сквозной слой промпт-шаблонов. Работает под Яндекс и под Google. Подключается к Метрике, Roistat и провайдерам SERP.
Ставим под ключ на серверах клиента. В первую неделю настраиваем промпты под стиль ваших готовых статей и редакторские правила, чтобы платформа писала так же, как пишет ваша команда. Каждый модуль — единоразовый платёж, без подписок и абонентки; число пользователей в команде на цену не влияет. Клиенту достаётся рабочая инсталляция со всеми модулями и полный админский доступ. От запуска до прогона первого клиента через весь пайплайн обычно проходит около двух недель.
Зачем мы это всё собрали
Устали возить SEO-данные между десятью разными сервисами. Один сервис для семантики, второй для съёма позиций, третий для аналитики, четвёртый для генерации статей, пятый для отслеживания упоминаний бренда. И все они существуют отдельно друг от друга.
В реальной работе на одном клиенте это превращается в пять открытых вкладок, четыре подписки, два экспорта в Excel и одну Google-таблицу, в которой это всё сводится руками. Час работы аналитика на простую задачу — посмотреть, как продвигается клиент в этом месяце.
ИСПОЛИН собирает все эти данные в одну панель и связывает их через проект. Один аккаунт, шесть модулей, общая база. Экспорты в Excel и сведение руками уходят: данные ходят между модулями сами.
Дальше — обзор по платформе на примере живого клиента: шесть модулей, чуть-чуть истории, много скриншотов.
Кейс Love Forever
Действующий клиент — салон свадебных и вечерних платьев в Санкт-Петербурге. Что у него внутри платформы: 2204 ключа в 983 группах, 64 завершённых исследования конкурентов, 56 готовых статей, шесть прогонов GEO-аудита и регулярные замеры видимости в Алисе Нейро и ChatGPT. Используются все шесть модулей одновременно — на таком проекте видно, как они цепляются друг за друга.
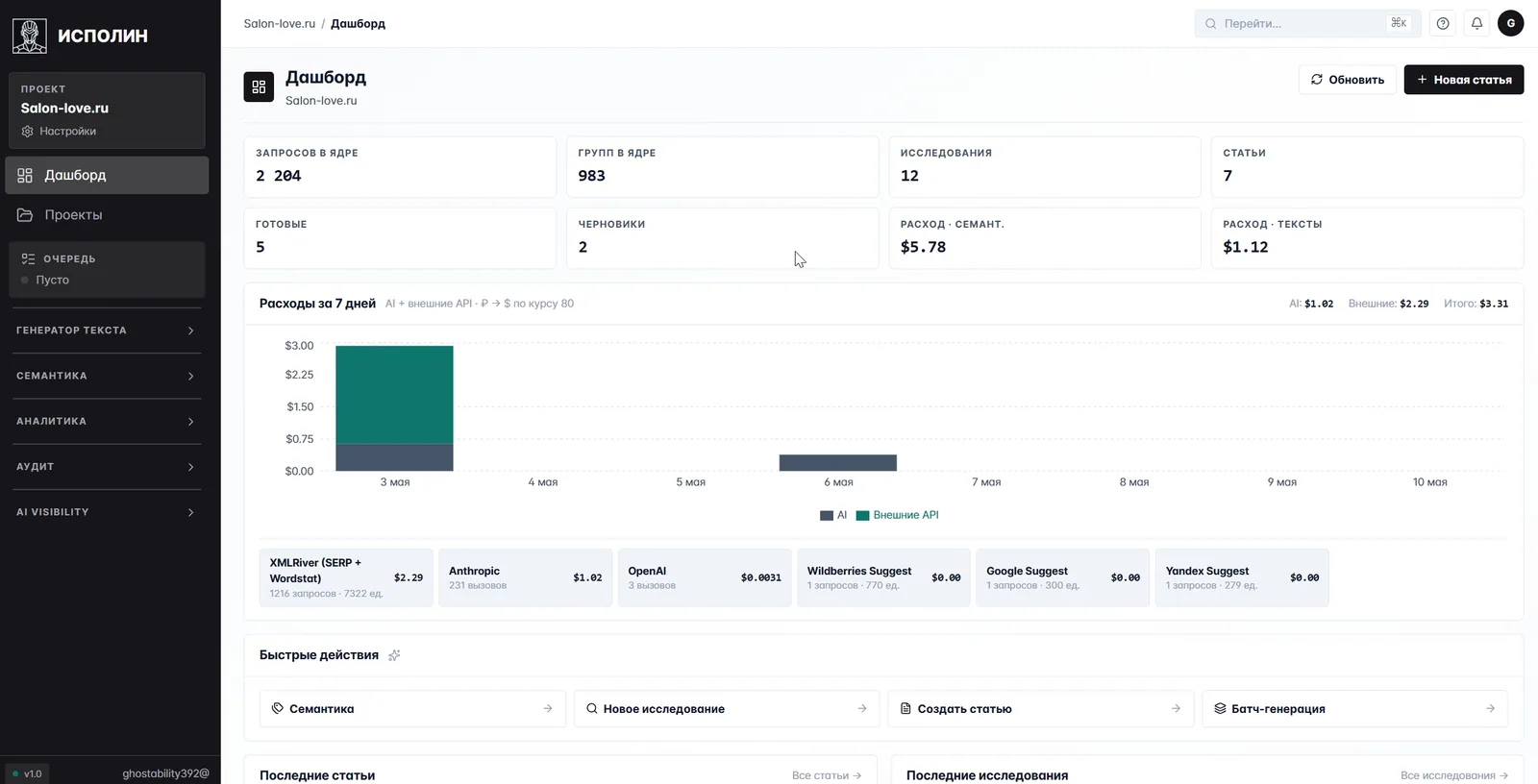
Дашборд — короткая сводка по проекту: за пять секунд видно состояние. Сверху размер ядра, число исследований и статей. Под ними блок расходов: на этом скриншоте за семь дней проект потратил 3,31 $, из них 1,02 $ на AI-генерацию и 2,29 $ на внешние API (XMLRiver SERP, Wordstat, поисковые подсказки). Без такого экрана легко потерять ощущение масштаба, особенно если проектов несколько.
Модуль 01 — Семантика
Первое, с чего начинается любой проект. Из стартового списка ключей или вообще из голого описания бизнеса собирается полное ядро со скорингом, частотами и кластеризацией.
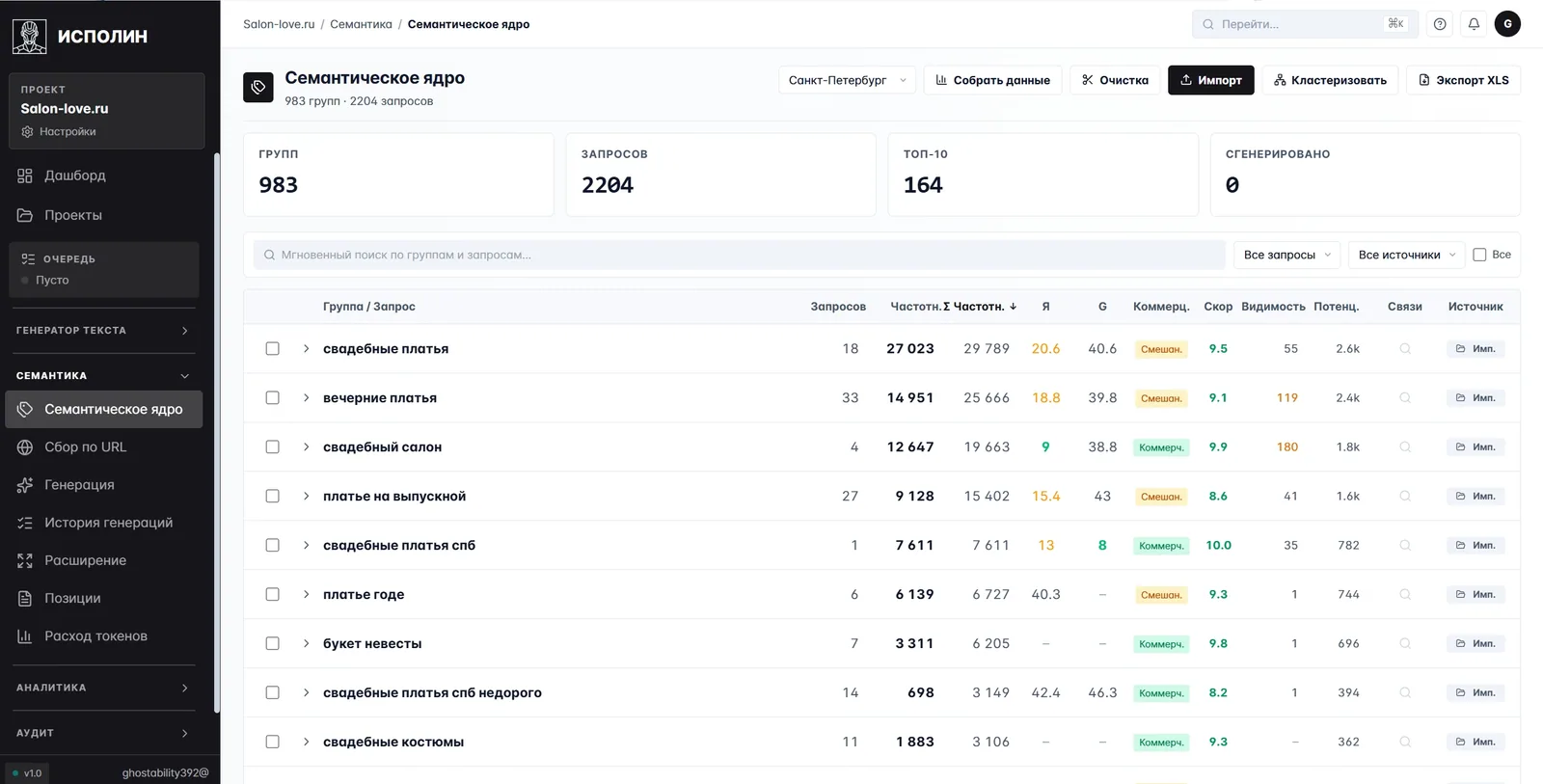
В таблице по каждому запросу видно частоту на Яндексе и Google, тип (коммерческий, смешанный, информационный), композитный скор от 0 до 10 и потенциал трафика. На скрине: «свадебные платья» — 27 023 запросов с потенциалом 2,6 тыс. визитов; «свадебный салон» — 12 647 с потенциалом 1,8 тыс. Цифры собираются и обновляются автоматически. Аналитик не лезет в Wordstat и не сводит экспорты руками.
Само ядро редко собирают одной кнопкой — обычно расширяют существующее. Поэтому сразу под ядром живёт раздел «Расширение».
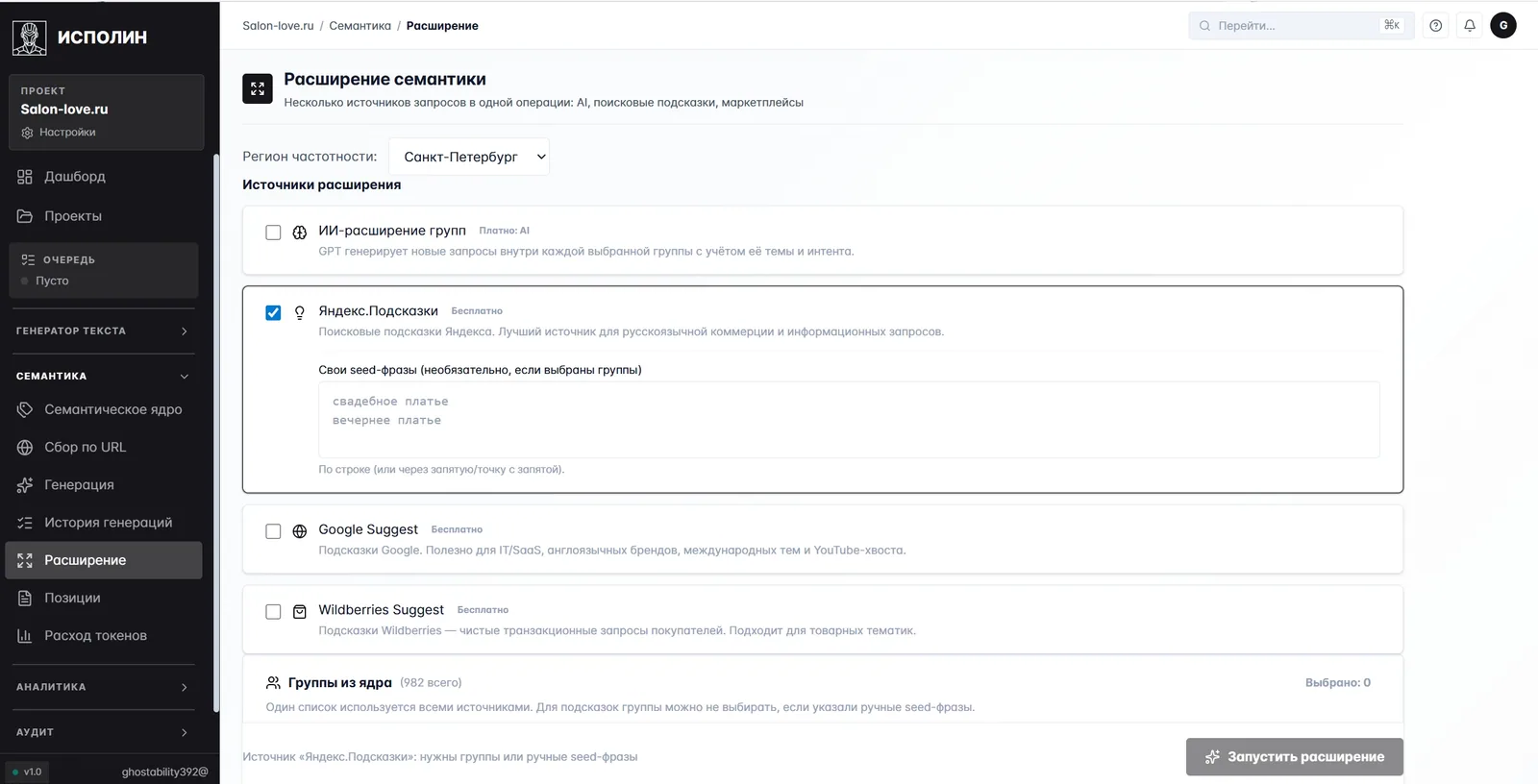
Четыре источника на одном экране. AI-расширение от GPT работает внутри тематической логики бизнеса и догадывается до запросов, которые поисковые подсказки не предложат. Яндекс.Подсказки добивают коммерческий и информационный длинный хвост русской аудитории, бесплатно. Google Suggest пригодится для IT/SaaS и англоязычных тем. Wildberries Suggest даёт чистые транзакционные запросы для товарных тематик.
Когда после расширения ядро распухает до 5000+ запросов, на сцену выходит чистка.
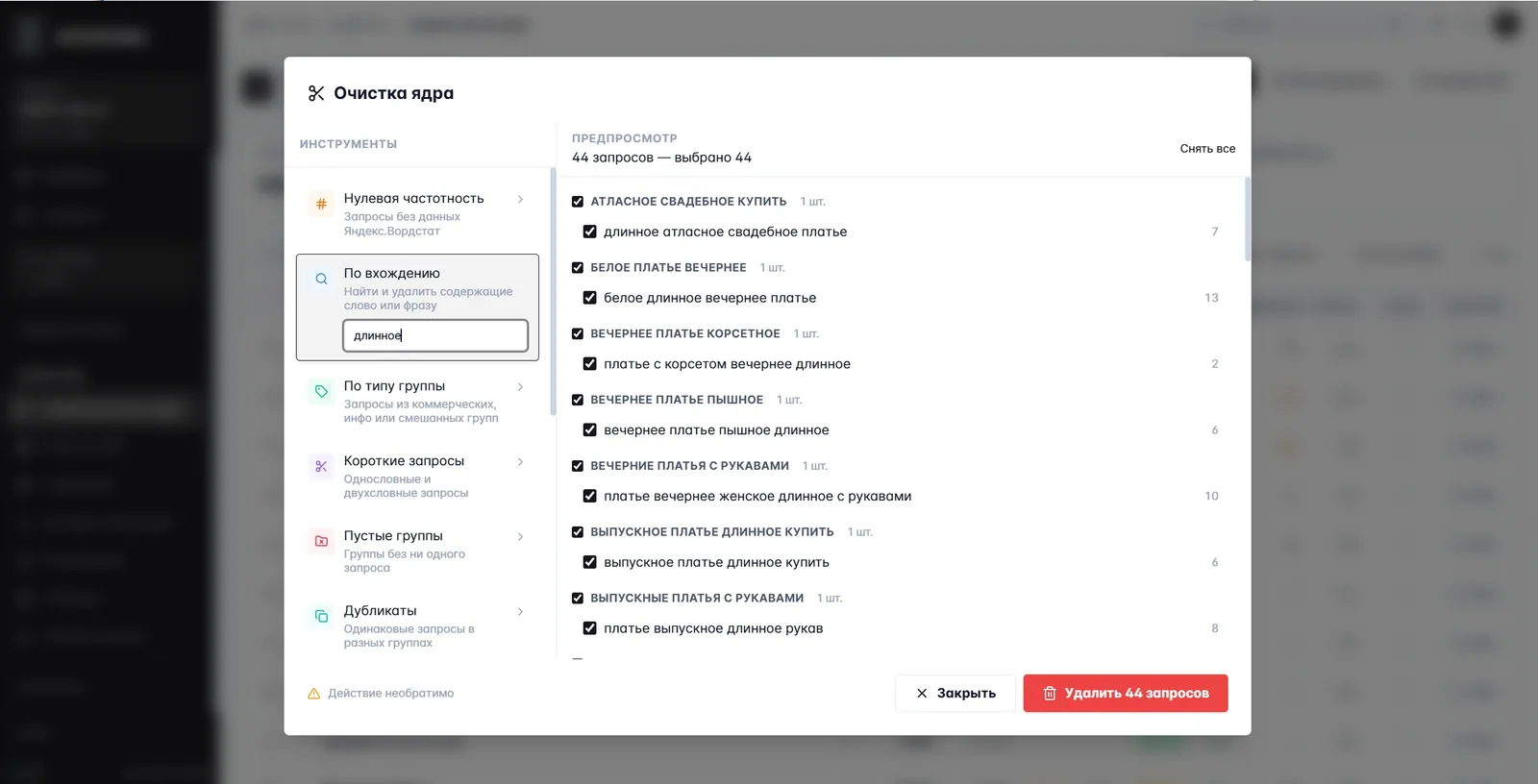
Шесть инструментов чистки. Слева — что искать (запросы без частоты, по вхождению слова, по типу группы, односложные, пустые группы, дубликаты), справа — превью того, что будет удалено. Слепых массовых удалений тут не бывает: видишь, что вылетит, и подтверждаешь. На скрине найдено 44 запроса с вхождением «длинное», их можно убрать одним нажатием.
Параллельно с ручной семантикой работает «Сбор по URL» — парсер, который вытягивает ядро из готового сайта.
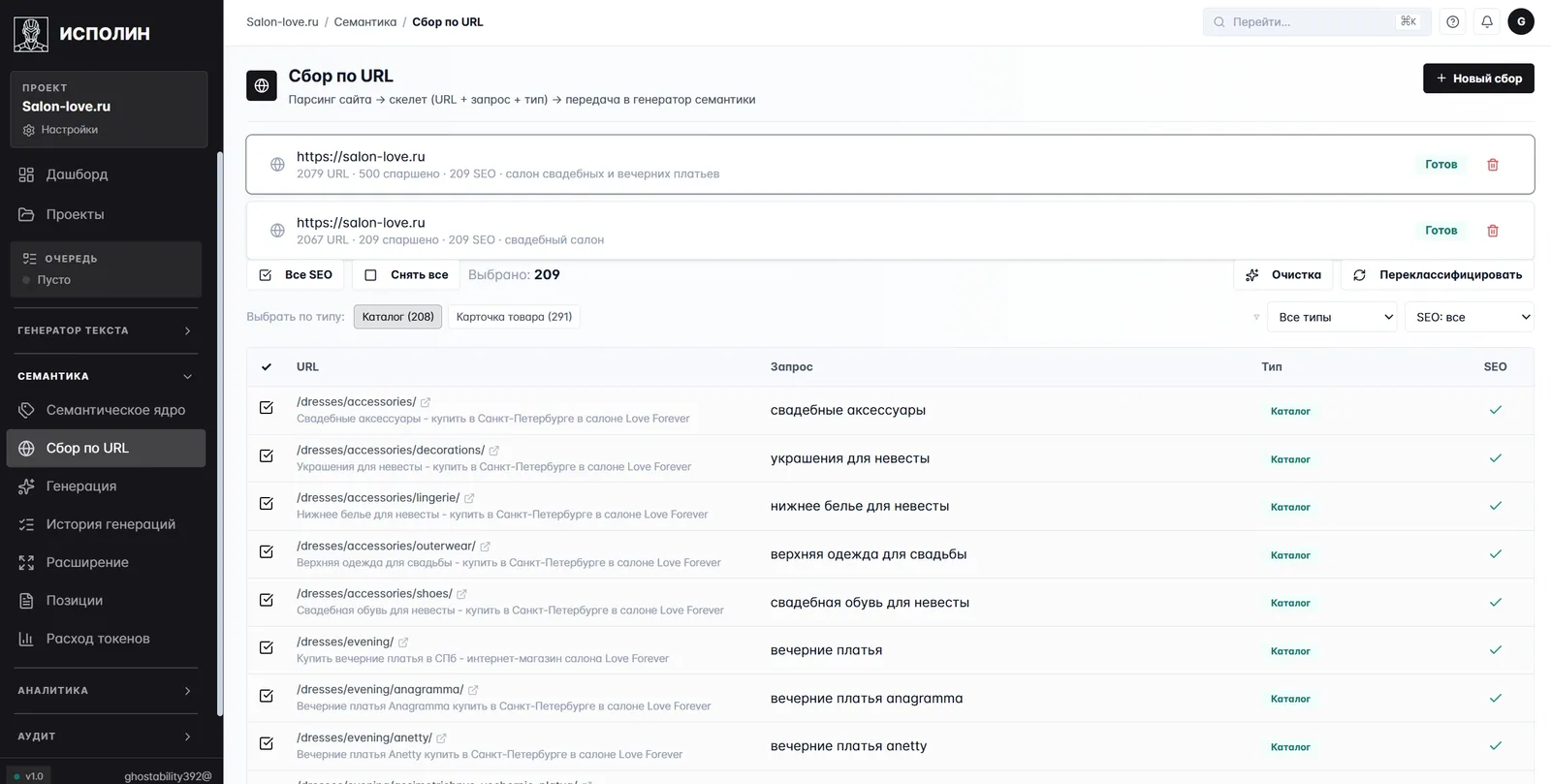
Парсер обходит сайт целиком, оставляет SEO-релевантные страницы, для каждой определяет тип (каталог, карточка, посадочная) и подбирает основной запрос с проверкой через SERP. На скрине: из 2079 URL на сайте отобрано 209 значимых, к каждому привязан запрос и тип. Это материал, на котором дальше строятся ТЗ для статей и съём позиций.
И отдельный сценарий — кластеризация по поисковой выдаче, когда ядро уже собрано, но нужно понять, какие запросы из разных групп должны жить на одной странице.
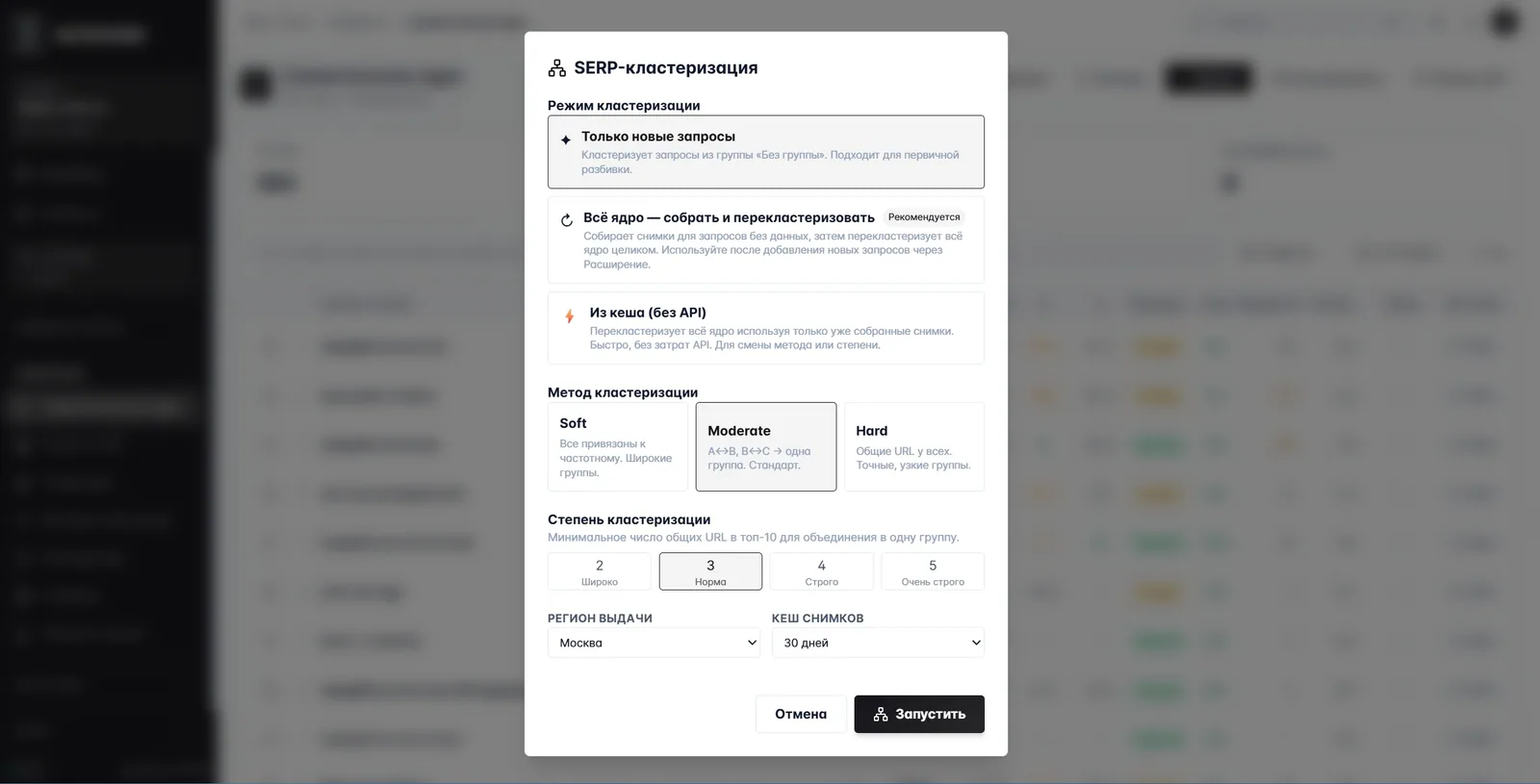
Метод выбирается под задачу. Soft широко группирует по частотному. Moderate — стандартная связка через цепочки общих URL. Hard режет по строгому пересечению. Параметр строгости — сколько общих URL в ТОП-10 нужно, чтобы запросы попали в одну группу. На таком сайте, как Salon-love, обычно достаточно Moderate с порогом 3: середина по индустрии, чистые группы без слишком крупных «комков».
Отдельно от семантики живёт мониторинг позиций, но смотреть его удобнее тут же — запрос и его позиция должны быть рядом.
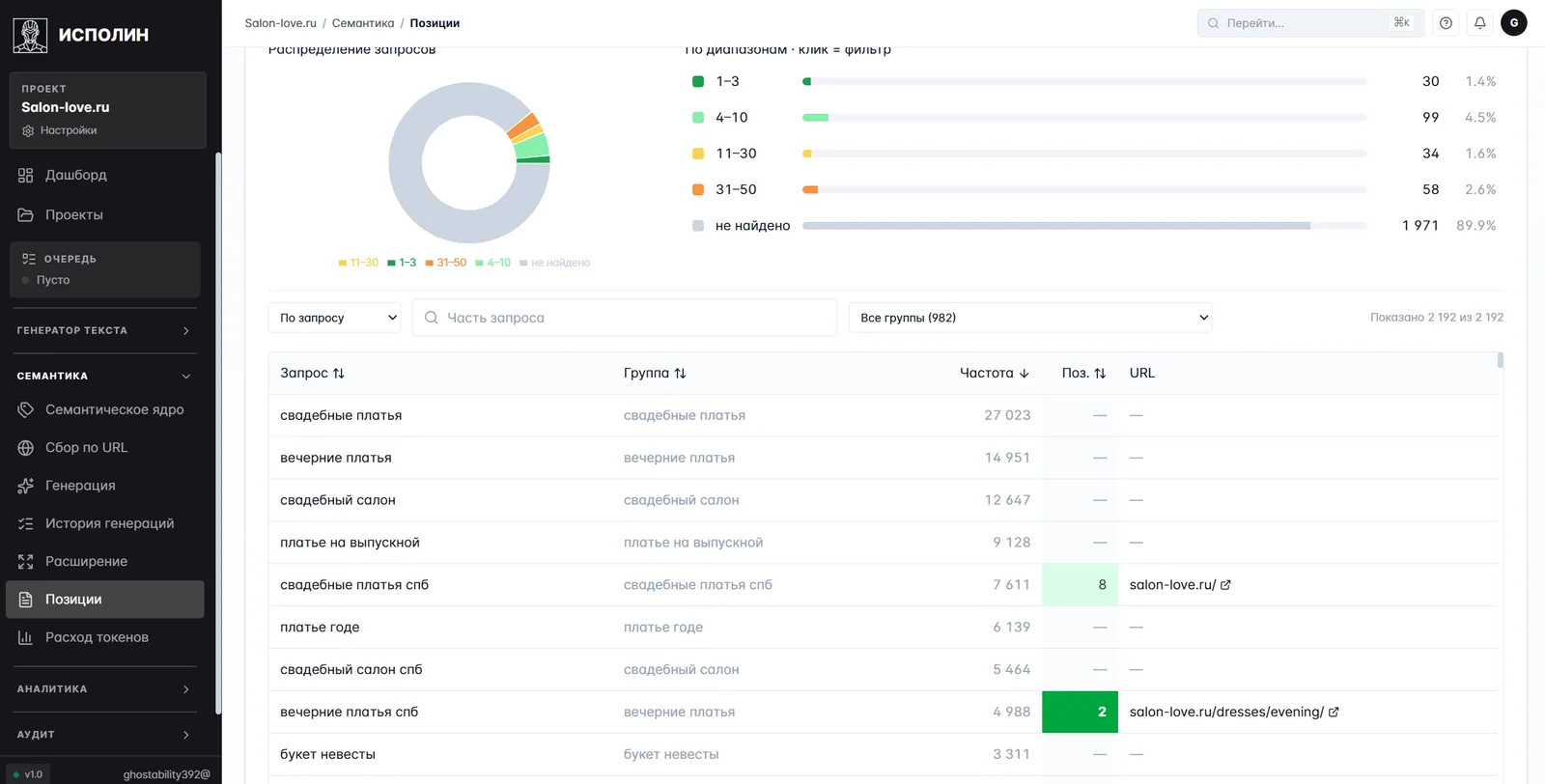
Кольцевая диаграмма распределения по диапазонам, ниже — таблица со снимками позиций. Смотришь на цвет: красное — «не найдено», то есть под запрос вообще нет страницы; жёлтое — позиции 11–30, болевая зона, где надо точечно работать; зелёное (1–3 и 4–10) — вход в выдачу. На Salon-love сейчас 30 запросов в ТОП-3 и 99 в ТОП-10, остальные требуют либо новой страницы, либо доработки существующей.
Ядро остаётся внутри проекта и им сразу пользуются остальные модули. Контент-пайплайн берёт ключи отсюда. Аналитика мониторит позиции по ним же. Прогноз трафика считается по этому же ядру. Excel из цикла выпадает.
Модуль 02 — Контент
Второй модуль — конвейер от ключа до готовой статьи. Пять шагов: исследование конкурентов, ТЗ, написание, проверка, редактура. У каждого шага свои данные и свой промпт-шаблон.
Шаг 1. Исследование конкурентов по запросу
Из ключа в семантике запускается исследование. Платформа открывает поисковую выдачу, парсит ТОП-10 сайтов, разбирает их на структурные элементы и складывает в один отчёт.
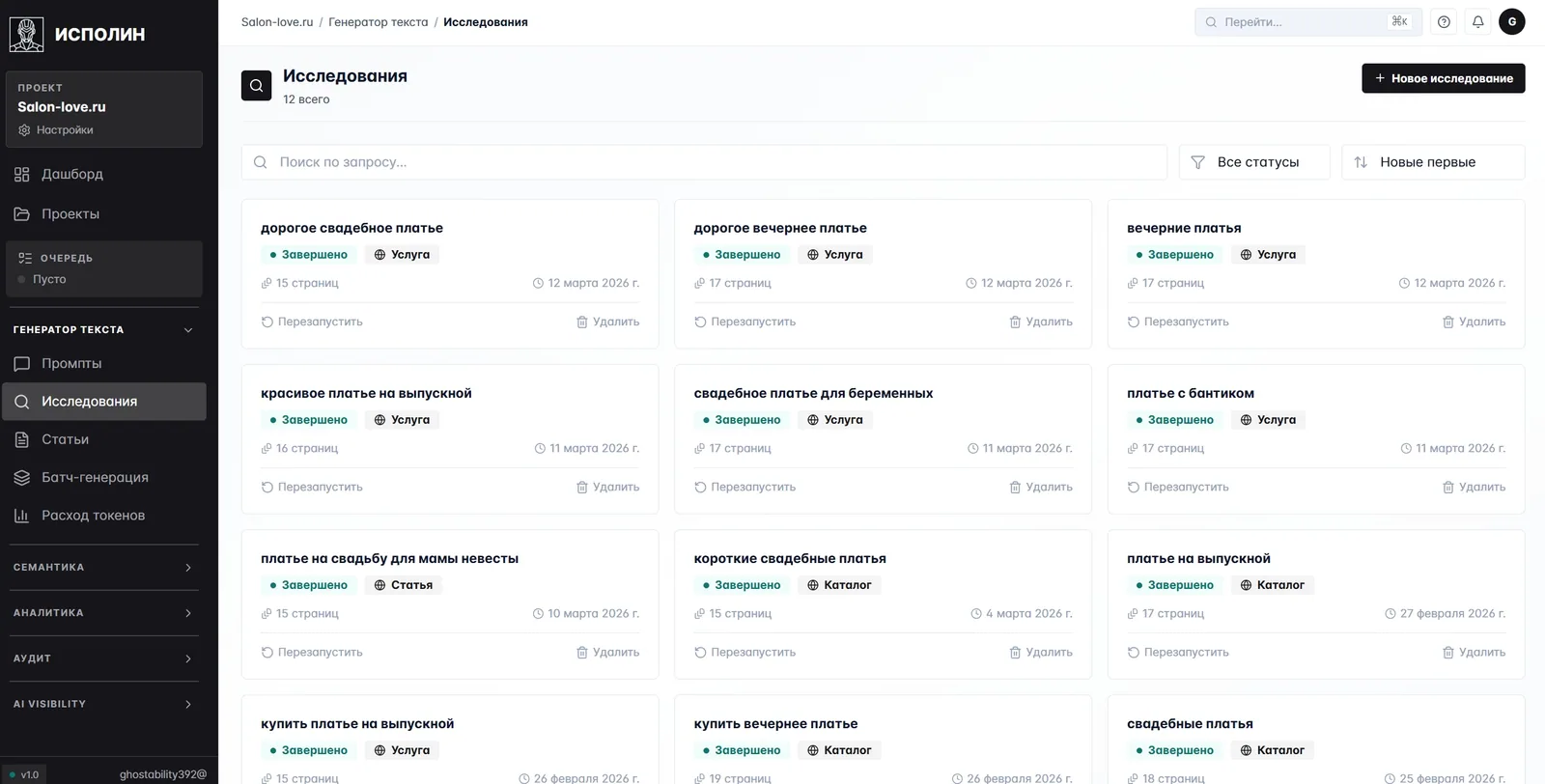
На карточке каждого исследования — запрос, тип страницы, под который собрано, число найденных и проанализированных URL, дата. На проекте есть исследования и под услуговые страницы (платья на выпускной, вечерние), и под каталоги (короткие свадебные), и под статьи. Один запрос — один отчёт, который дальше пойдёт в ТЗ.
Внутри одного исследования картина детальнее.
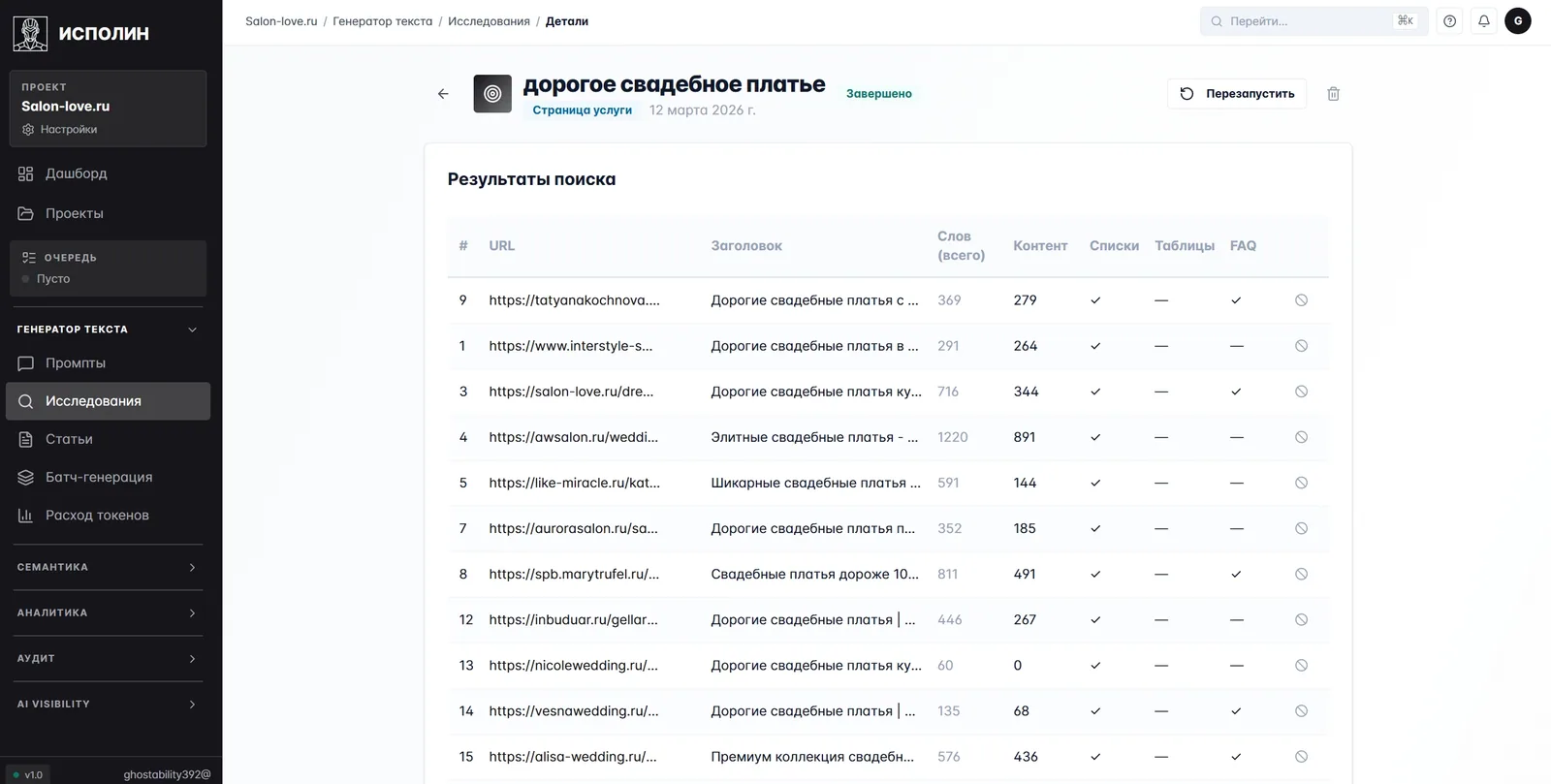
Это рабочая страница исследования. Колонки — то, что важно копирайтеру и модели: сколько слов всего на странице у каждого конкурента, сколько из них содержательного контента (не футер и боковые блоки), есть ли списки, таблицы, FAQ-блоки. На скрине у awsalon.ru объём 1220 слов и 891 содержательного контента — самая «толстая» статья в выдаче, явный лидер. У nicolewedding всего 60 слов: редирект или пустая страница. По этой картинке копирайтер уже знает, на какой объём писать и какие структурные блоки добавлять обязательно.
Шаг 2. Автоматическое ТЗ
Из исследования автоматически собирается техническое задание. Внутри — целевой объём, карта интентов и карта разделов под нужные подтемы.
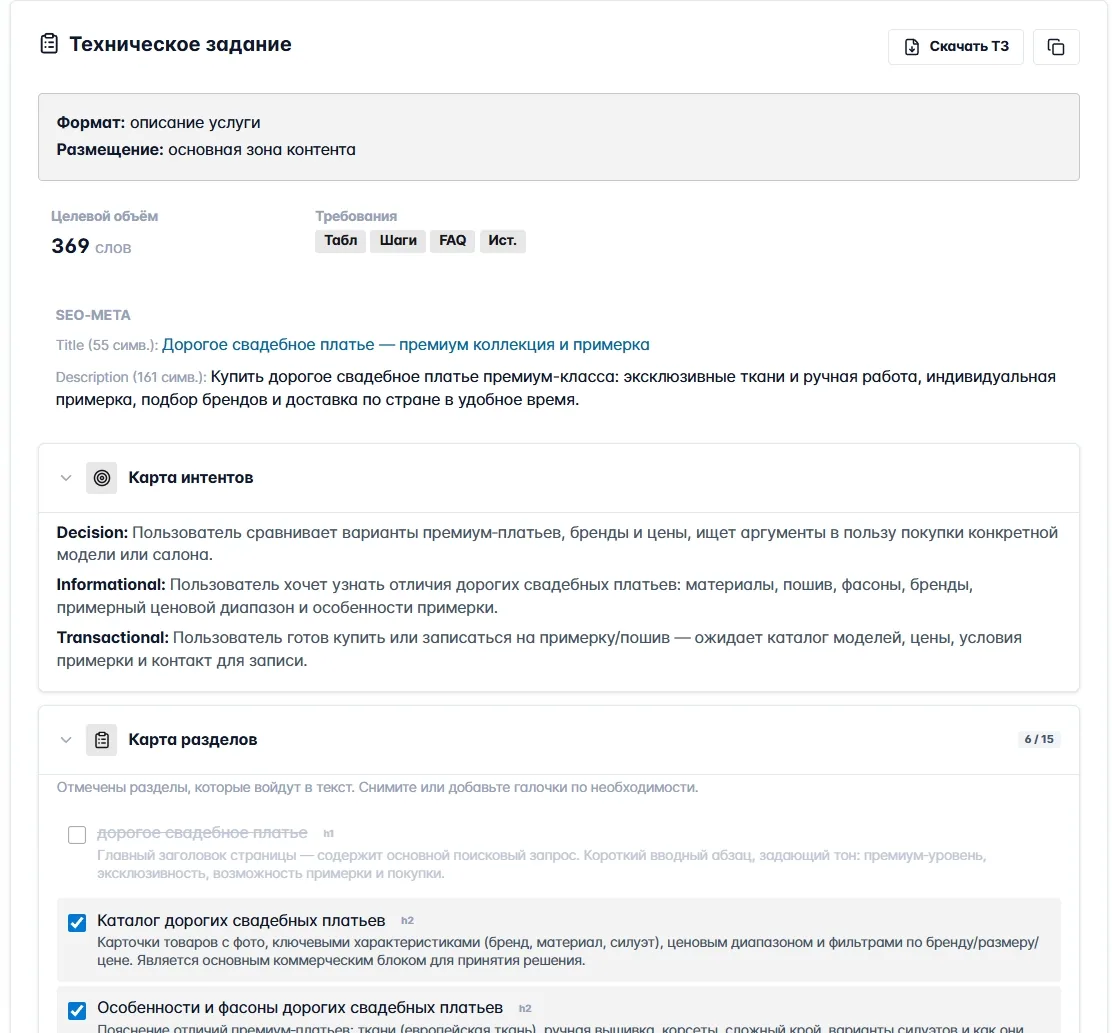
Сверху — формат страницы и целевой объём (тут 369 слов, среднее по конкурентам). Дальше готовые SEO-мета: Title 55 символов, Description 161 — оба попадают в лимиты. Карта интентов делит то, что хочет пользователь, на три колонки: Decision (что решает), Informational (что хочет узнать), Transactional (готов ли купить). Карта разделов — дерево заголовков H2 с короткими описаниями: главный заголовок, «Каталог», «Особенности и фасоны», «Брендовая селекция» и так далее. ТЗ можно скачать отдельным файлом и отдать копирайтеру или сразу запустить генерацию.
Шаги 3–4. Статья: написание и проверка
ТЗ уходит в редактор, дальше идут два AI-этапа: написание и проверка. Проверку делает другая модель, которая текст не писала. Модель проверяет модель, и только после этого статья попадает к редактору-человеку.
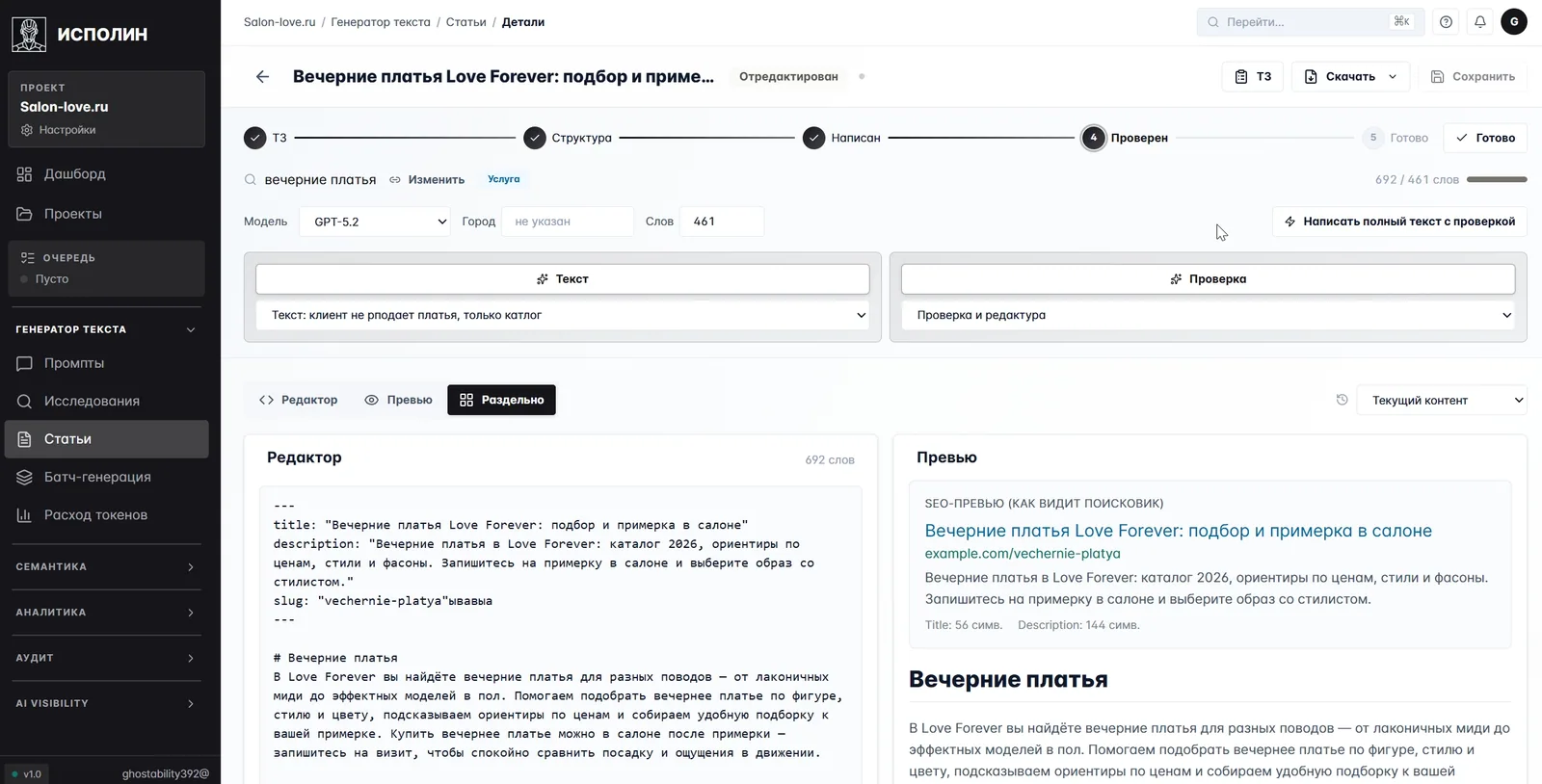
Пять шагов сверху — весь жизненный цикл статьи. Каждый шаг отдельная задача: ТЗ собирается из исследования (Шаг 1), структура — из подтем выдачи, написание — выбранной моделью, проверка — другой моделью, дальше финальная редактура. По точкам видно прогресс: четыре шага закрыты, на пятой статья «Готово». Слева markdown-редактор, справа SEO-превью «как видит поисковик». Цифры под пресетами «Текст» и «Проверка» — конкретные конфигурации промптов проекта; владелец настраивает их один раз. Дальше все статьи пишутся в одном тоне.
Шаг 5. Батч-генерация
И сверху над всем — батч. По одной статье руками никто не запускает; запускают сразу пакетом из 30–50 ключей.
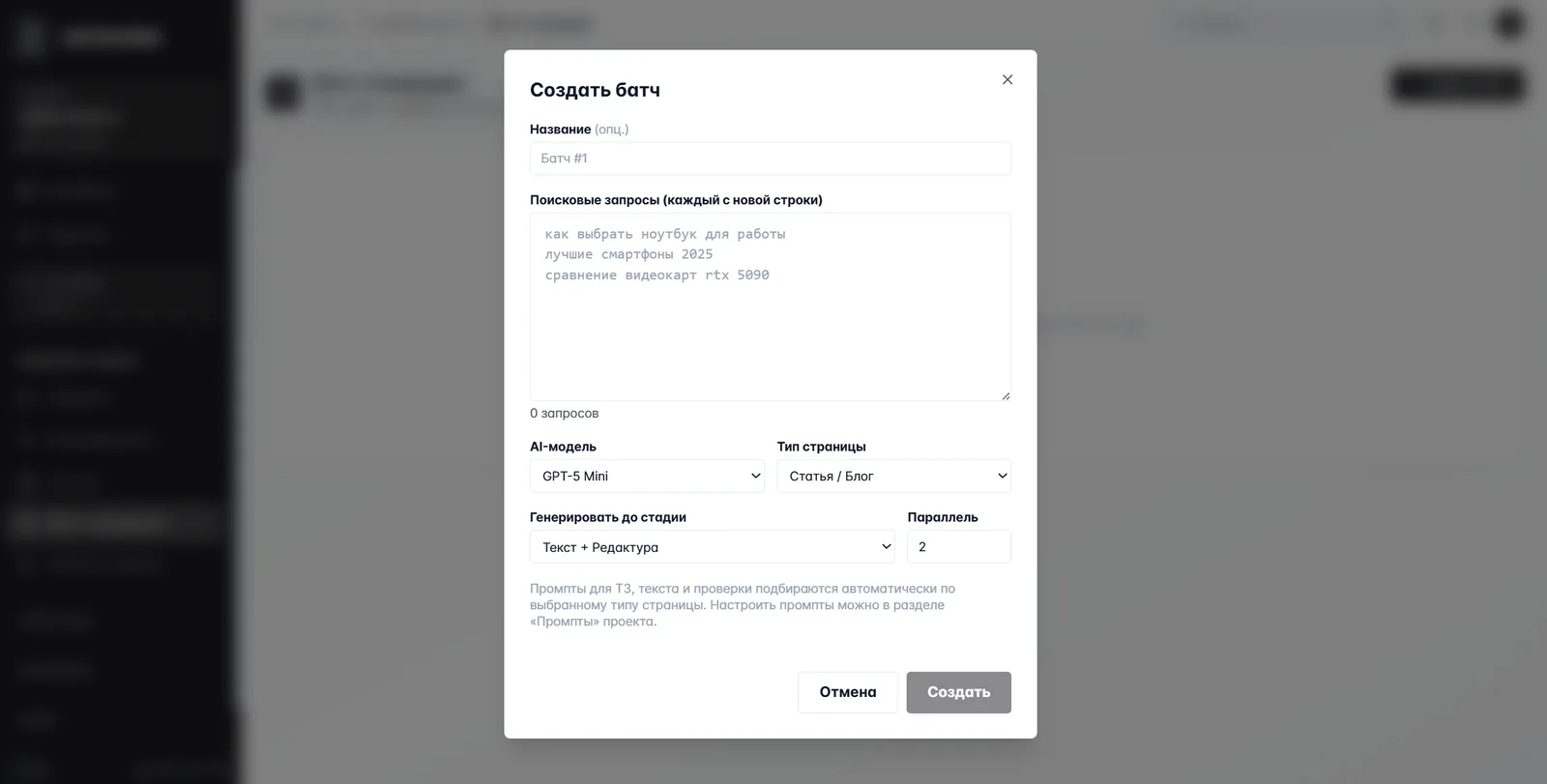
Заполняется одно модальное окно: название батча, список запросов из вашего ядра, тип страниц, до какой стадии гнать (можно остановить на ТЗ, можно прогнать до полного текста с проверкой), сколько потоков параллельно. Промпты подбираются автоматически под выбранный тип страницы — для блога одни, для коммерческих посадочных другие.
Дальше воркеры параллельно прогоняют исследования и черновики, прогресс виден в реальном времени. Если что-то падает — таймаут на SERP, ошибка у LLM-провайдера, битая страница конкурента — задача помечается как проблемная и перезапускается отдельно. Из-за одной статьи весь батч не падает.
На выходе — список готовых статей
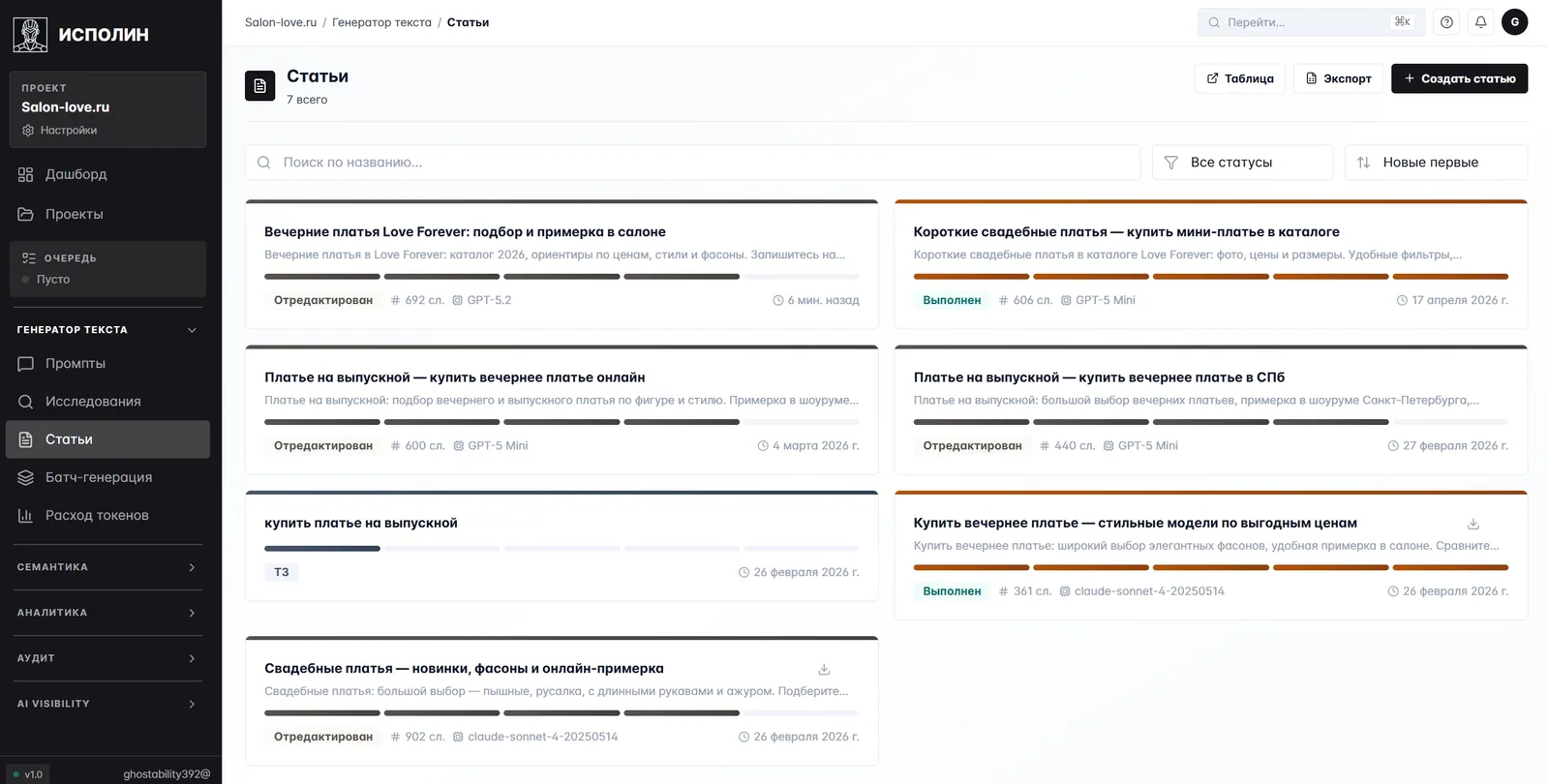
На карточке каждой статьи — статус, объём в словах, какая модель использовалась и дата. На Salon-love часть статей собрана GPT-5.2 (большие материалы, 600–900 слов), часть — GPT-5 Mini (короткие коммерческие, 300–600 слов), часть — claude-sonnet-4 (длинные обзорные, под 900 слов). Под каждую задачу своя модель. Всего на проекте сейчас 56 статей.
Модуль 03 — Аналитика
Третий модуль — данные о трафике, позициях и работах. Подключается к Яндекс Метрике через её API, опционально — к Roistat для финансовой картины.
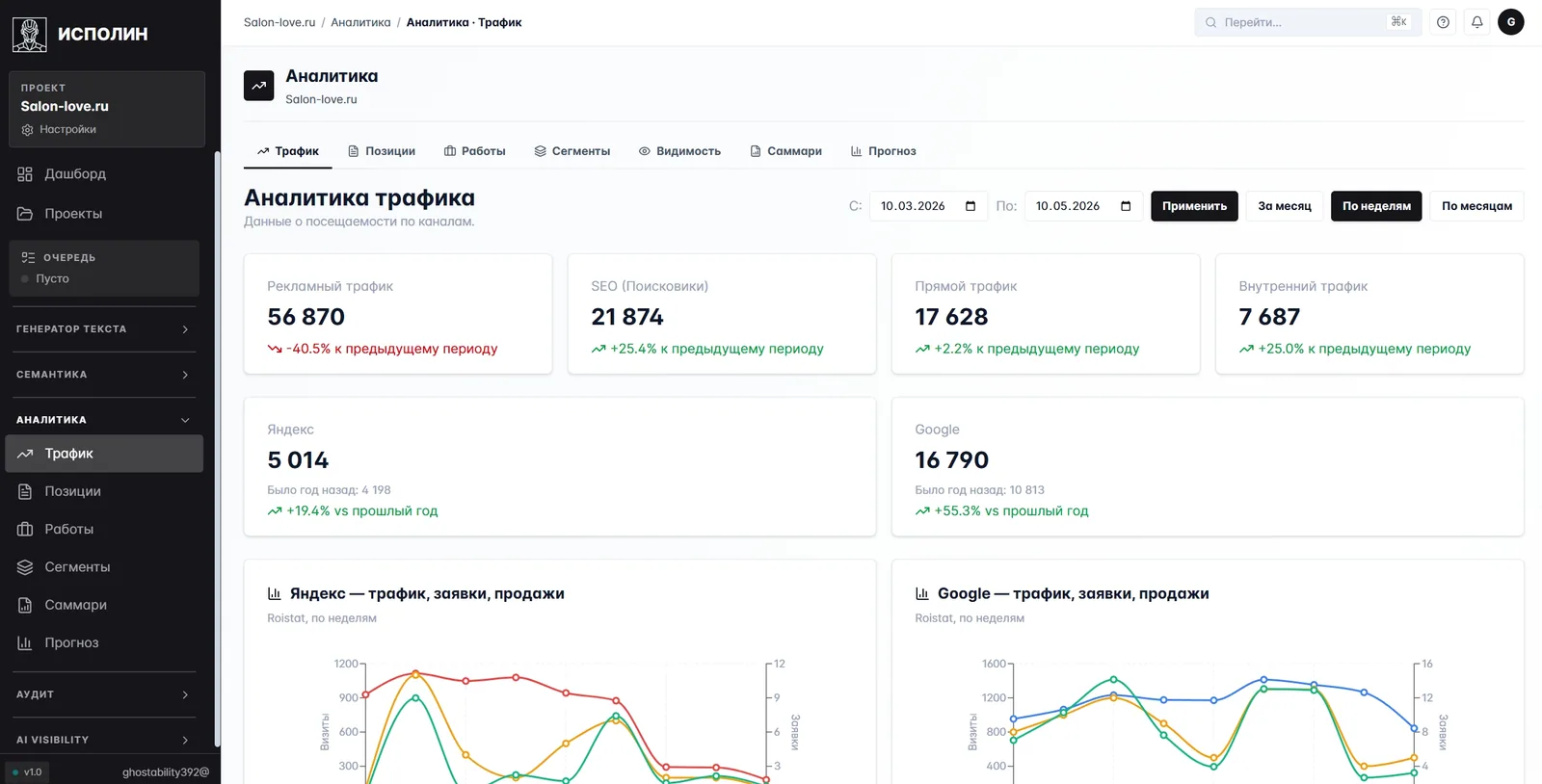
Картинка боевая. SEO-трафик за месяц — 21 874 визита, +25,4% к предыдущему периоду. Google — 16 790 визитов с приростом 55,3% за год. Яндекс — 5014 с +19,4% за год. Под цифрами — графики Roistat: видно сезонность по визитам и заявкам в одной картинке, как разошёлся Google и Яндекс. SEO-специалисту больше не нужно открывать Метрику, копировать в таблицу и ждать данных по Roistat от бухгалтерии: всё в одной панели.
Есть и более редкий, но важный экран — прогноз трафика.
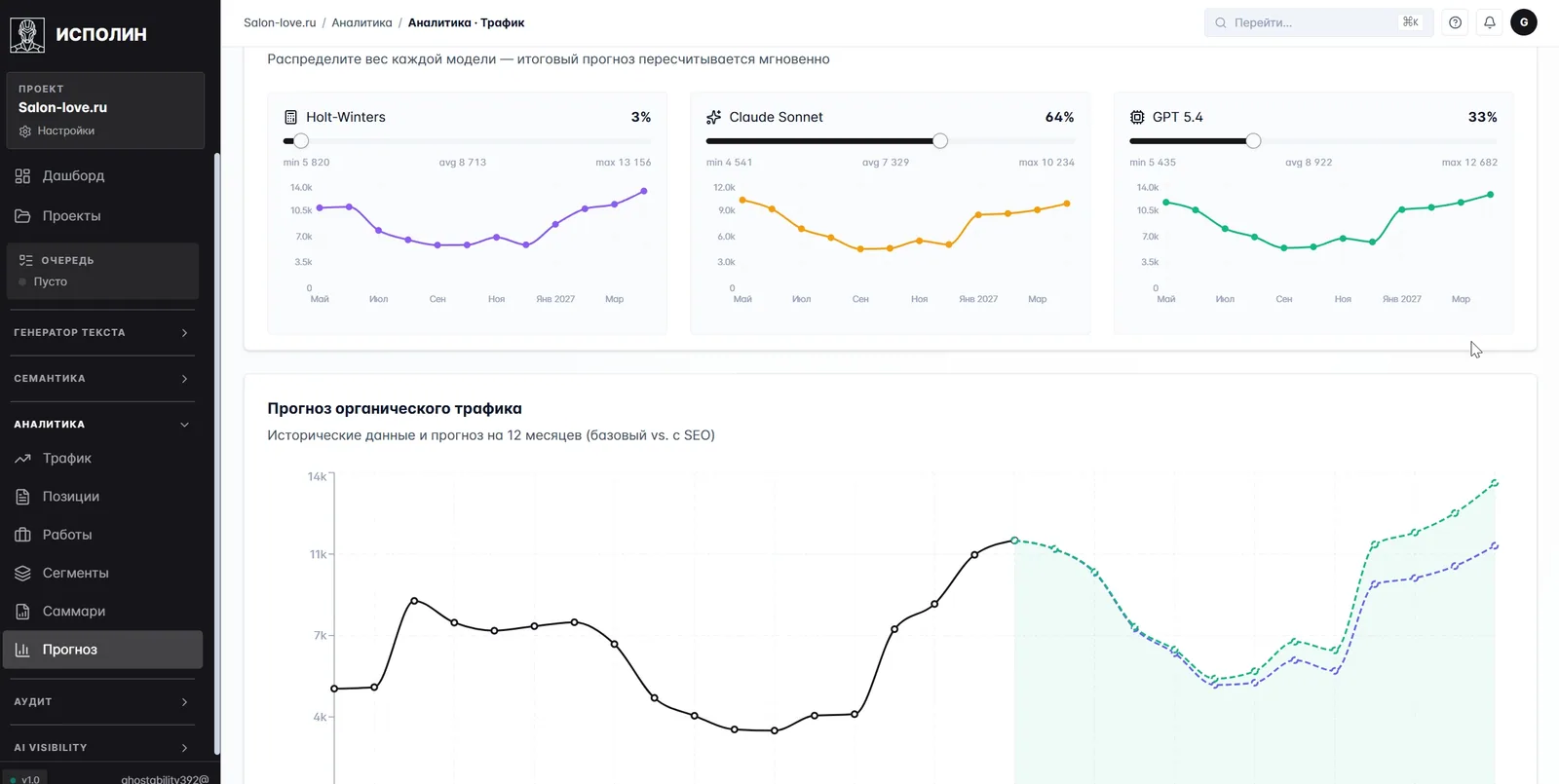
Прогноз считается ансамблем из трёх моделей. Holt-Winters — классика статистики, ловит сезонность. Claude Sonnet — большая языковая модель, хорошо чувствует контекст бизнеса. GPT 5.4 — третий голос для устойчивости. Веса гонятся ползунками. На скрине Claude доминирует (64%), GPT занимает треть (33%), а Holt-Winters взвешен на 3%, потому что у проекта нет ярко выраженной сезонности. Внизу — общий прогноз с двумя кривыми: базовая (что будет, если ничего не делать) и «с SEO» (с продвижением под текущее ядро). Менеджер видит горизонт года и понимает, куда движется проект.
Модуль 04 — GEO-аудит
Четвёртый модуль — про новый слой работы, который появился с приходом Алисы AI и ChatGPT. Аудит проверяет, готов ли сайт к тому, чтобы его цитировали AI-движки.
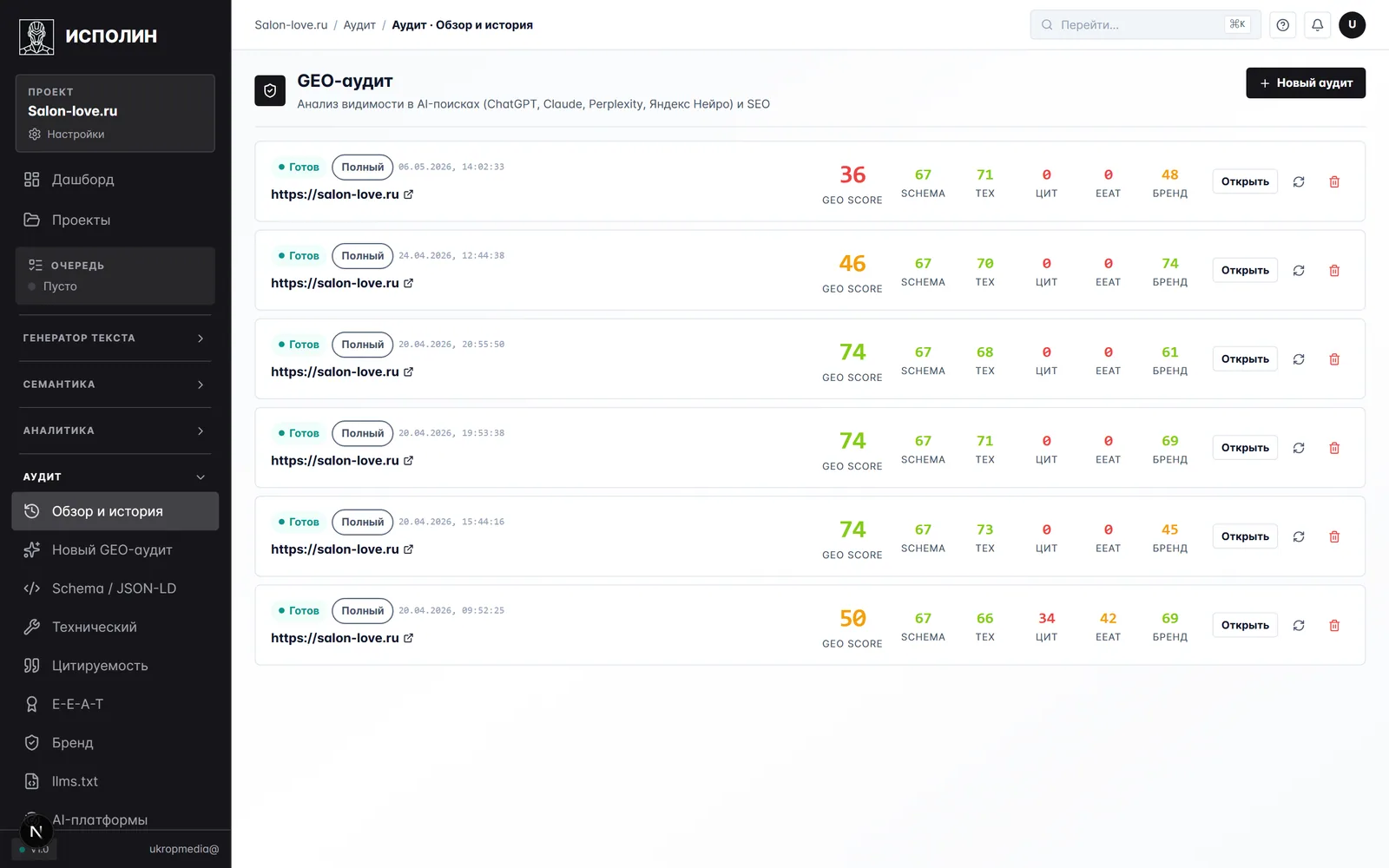
История замеров — отдельная страница, потому что аудит делается регулярно и важна динамика. На Salon-love шесть прогонов: композитный скор скакал между 36 и 74 баллами, видно, где после правок цифры подросли, где ушли назад. Каждая колонка — отдельная рубрика. По цитируемости и E-E-A-T у проекта пока проседание, по технической части и Schema — крепкие 67–73 балла.
Если зайти внутрь одного прогона, открывается полная картина по сайту.
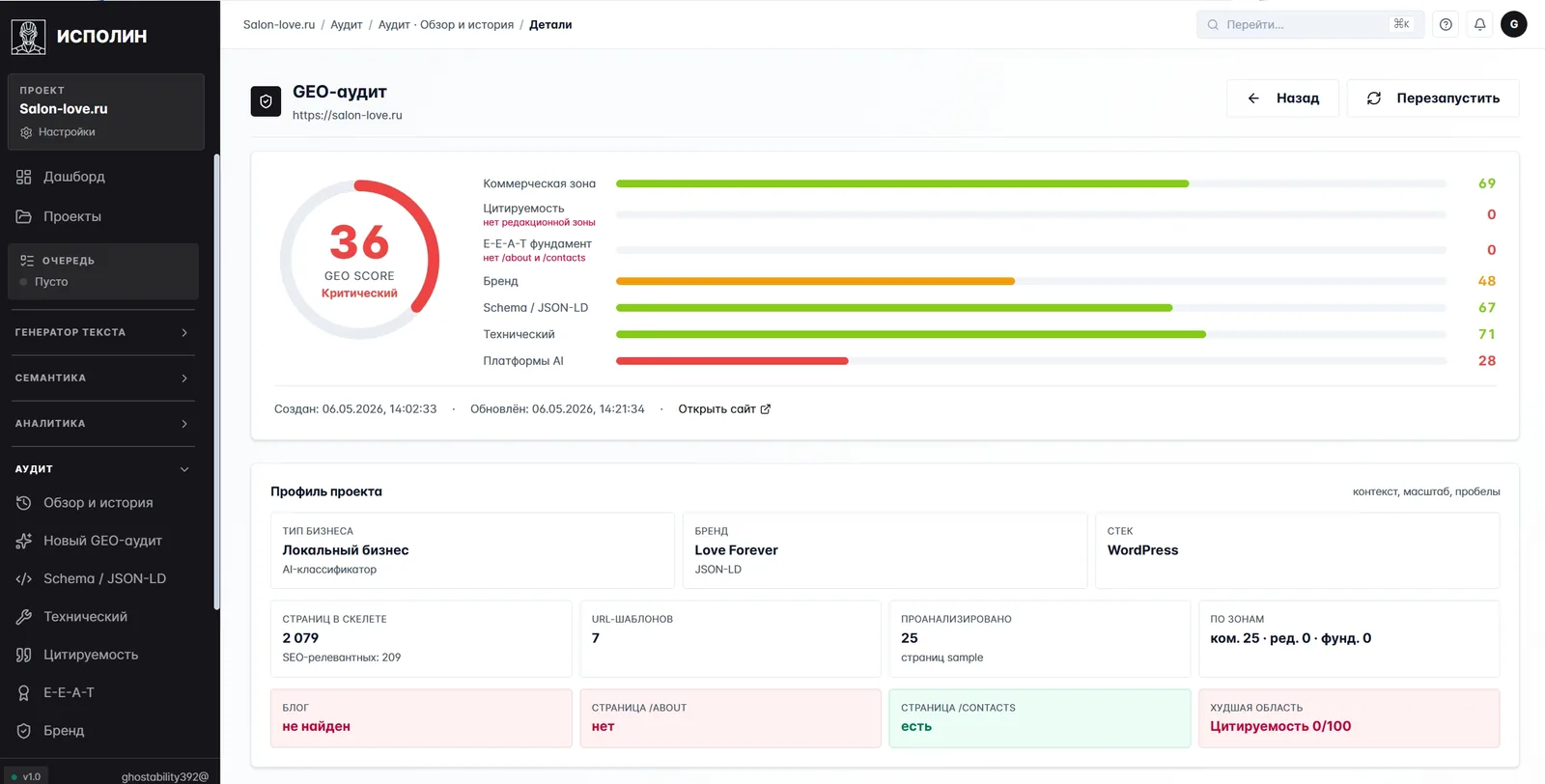
Слева — общий скор 36 баллов с пометкой «критический», справа — раскладка по семи осям. Сразу видно, что просели цитируемость (0/100, нет редакционной зоны) и фундамент (0, нет /about). В порядке: технический слой (71), Schema/JSON-LD (67), коммерческая зона (69). Без лишних вкладок — одна страница, и ясно, что чинить в первую очередь.
Часть проверок аудит не только ругает, но и сразу собирает.
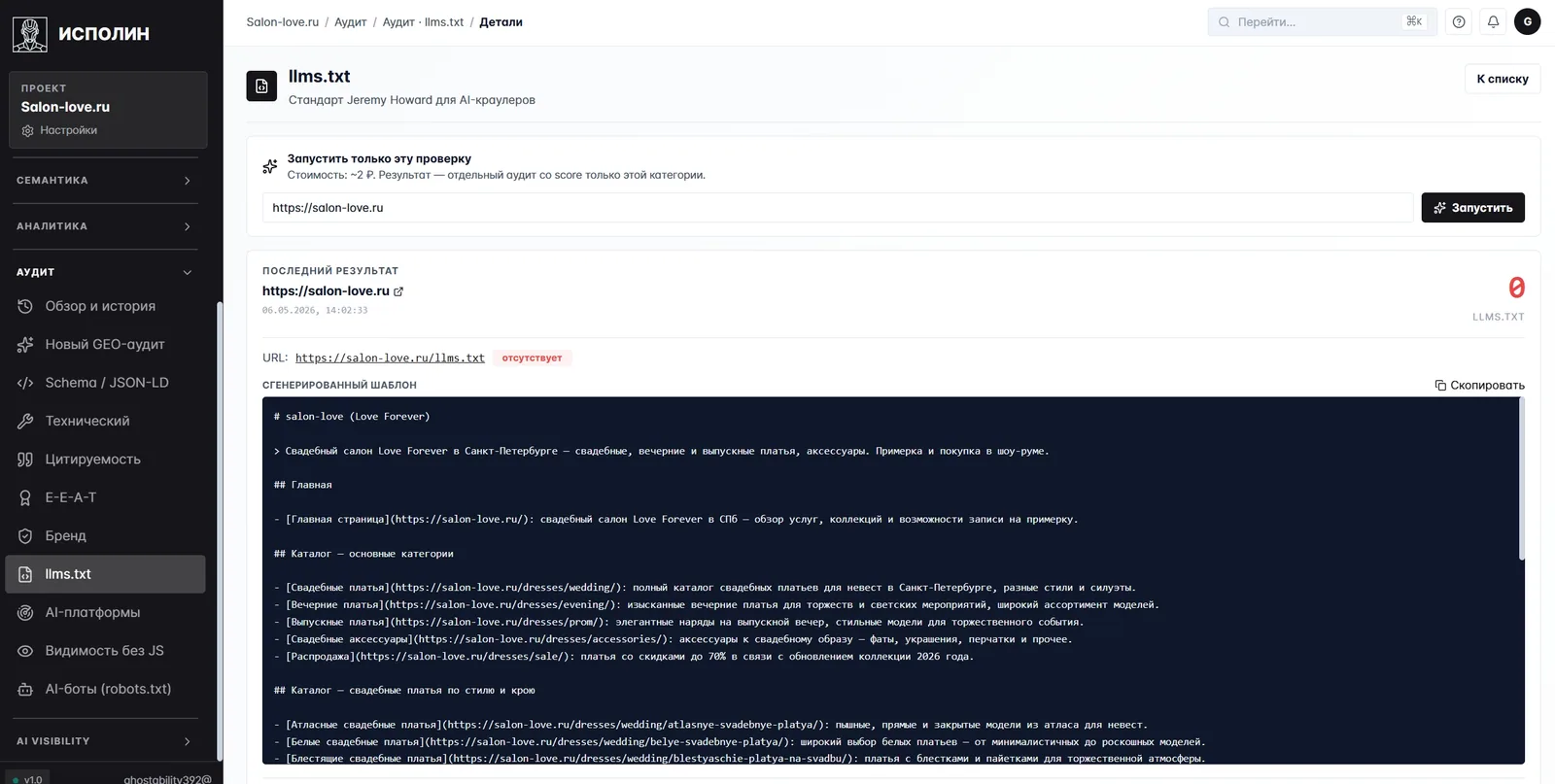
llms.txt — текстовый файл в корне сайта, описывающий важнейшие разделы для AI-движков (стандарт Джереми Хауарда, к 2026 году его читают все основные движки). Аудит либо проверяет существующий файл на полноту, либо собирает черновик с нуля по структуре сайта. На скрине — собранный шаблон для Salon-love: раздел «Главная», два раздела каталога (по типу платья и по крою), описания, прямые ссылки. Дальше копируется на сайт за пять минут.
Подробный разбор методики GEO-аудита — в отдельной статье. Здесь короткое: модуль есть, работает, прогон занимает около суток на средний сайт.
Модуль 05 — Видимость в LLM
Пятый модуль отвечает на вопрос, ради которого многие приходят. Цитируют меня в Алисе Нейро? В ChatGPT? Сколько раз за неделю? Какая позиция в ответе?
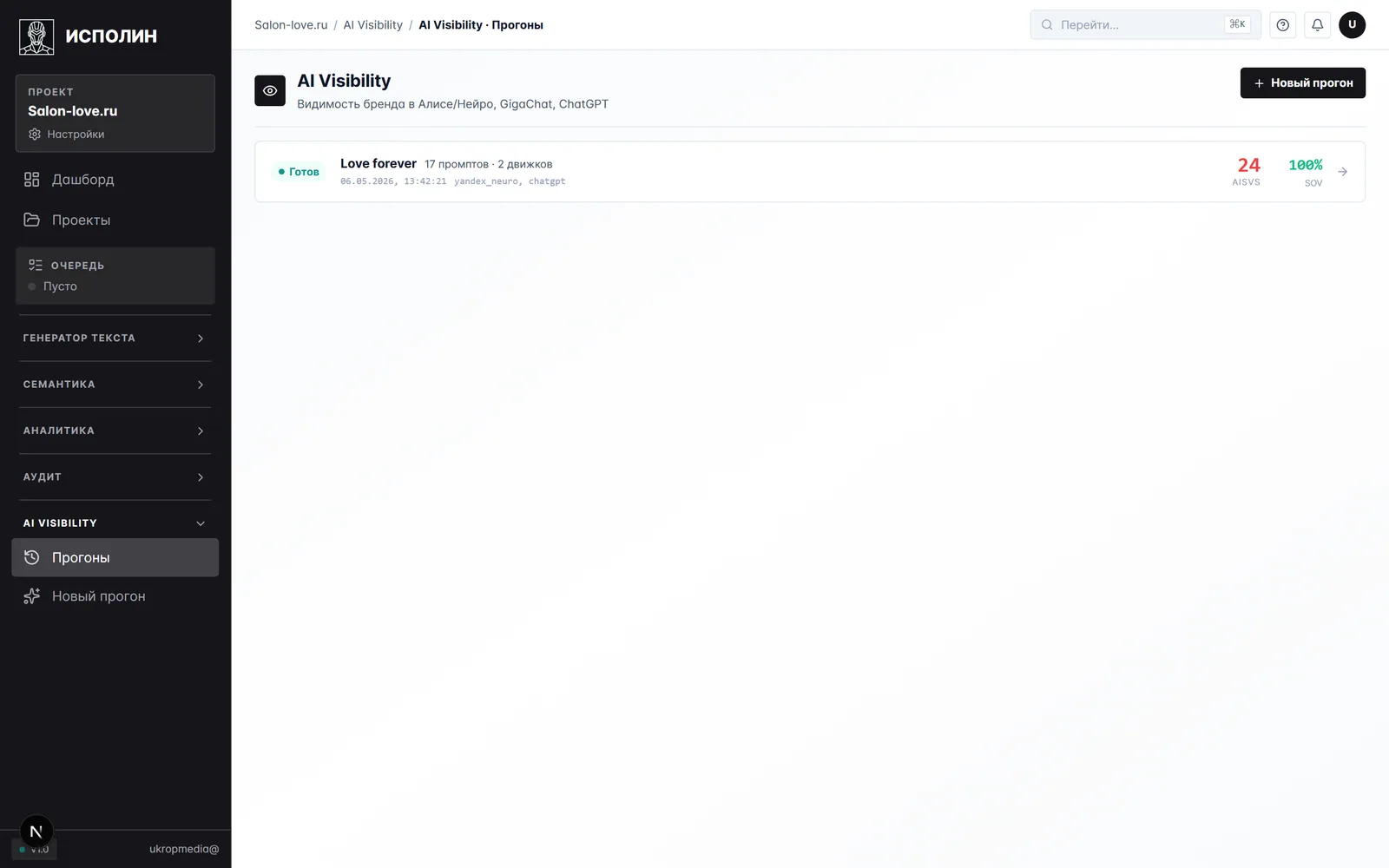
Прогон делается через корзину промптов, которую согласовываем под клиента. На Salon-love сейчас 17 промптов и два движка: Алиса Нейро и ChatGPT. По каждому прогону на странице списка видно дату, AISVS-индекс, движки. Если делать раз в две недели — получается ровный график, по которому ясно, движемся вверх или нет.
Внутри прогона — полная декомпозиция AISVS.
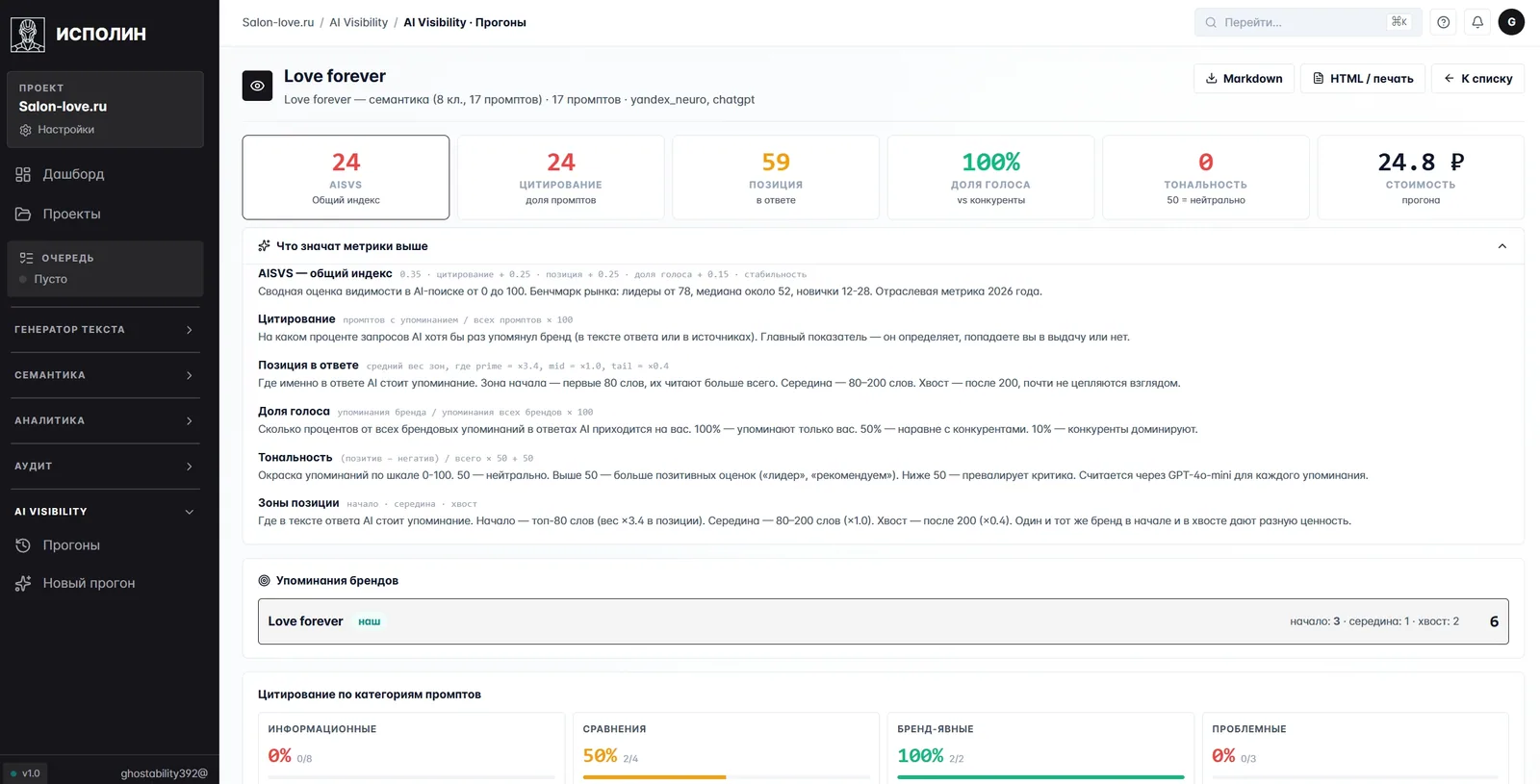
Шесть карточек сверху: четыре независимые метрики AISVS плюс тональность и стоимость прогона. На скрине общий индекс 24/100 (для салона свадебных платьев это нижняя зона, надо догонять), цитирование в 24% промптов (AI упомянул бренд в каждом четвёртом ответе), позиция 59 (середина ответа — читается хуже, чем начало), доля голоса 100% (когда упомянули — упомянули только нас, без альтернатив), тональность 0 (нейтральная). Стоимость прогона — 24,8 ₽ за оба движка.
Под карточками — подробное объяснение каждой метрики: что означает, откуда считается, какой бенчмарк рынка. Ниже — где именно бренд упоминается: 3 раза в начале ответа, 1 в середине, 2 в хвосте. Эти 6 упоминаний — основа для следующих итераций. Видно, в каких промптах бренда нет, и идёшь усиливать соответствующие страницы сайта.
Сквозной слой — Промпты и расход
Шестой блок проходит через все остальные. Промпт-шаблоны проекта.
Почему это важно. Одна и та же задача (написать абзац статьи, разобрать конкурента, скластеризовать ключи) на разных проектах формулируется по-разному. У стоматологии один тон, у интернет-магазина платьев — другой, у IT-агентства — третий. Захардкоженные внутрь платформы промпты дают усреднённый текст, который везде звучит одинаково.
Промпты в ИСПОЛИНе — редактируемые шаблоны на стороне клиента. Один раз настраиваешь их под стиль проекта (тон, лексика, стоп-слова, повторы), дальше все модули пользуются этими шаблонами.
Рядом — экран расхода токенов: видно, во что обходится каждый прогон.
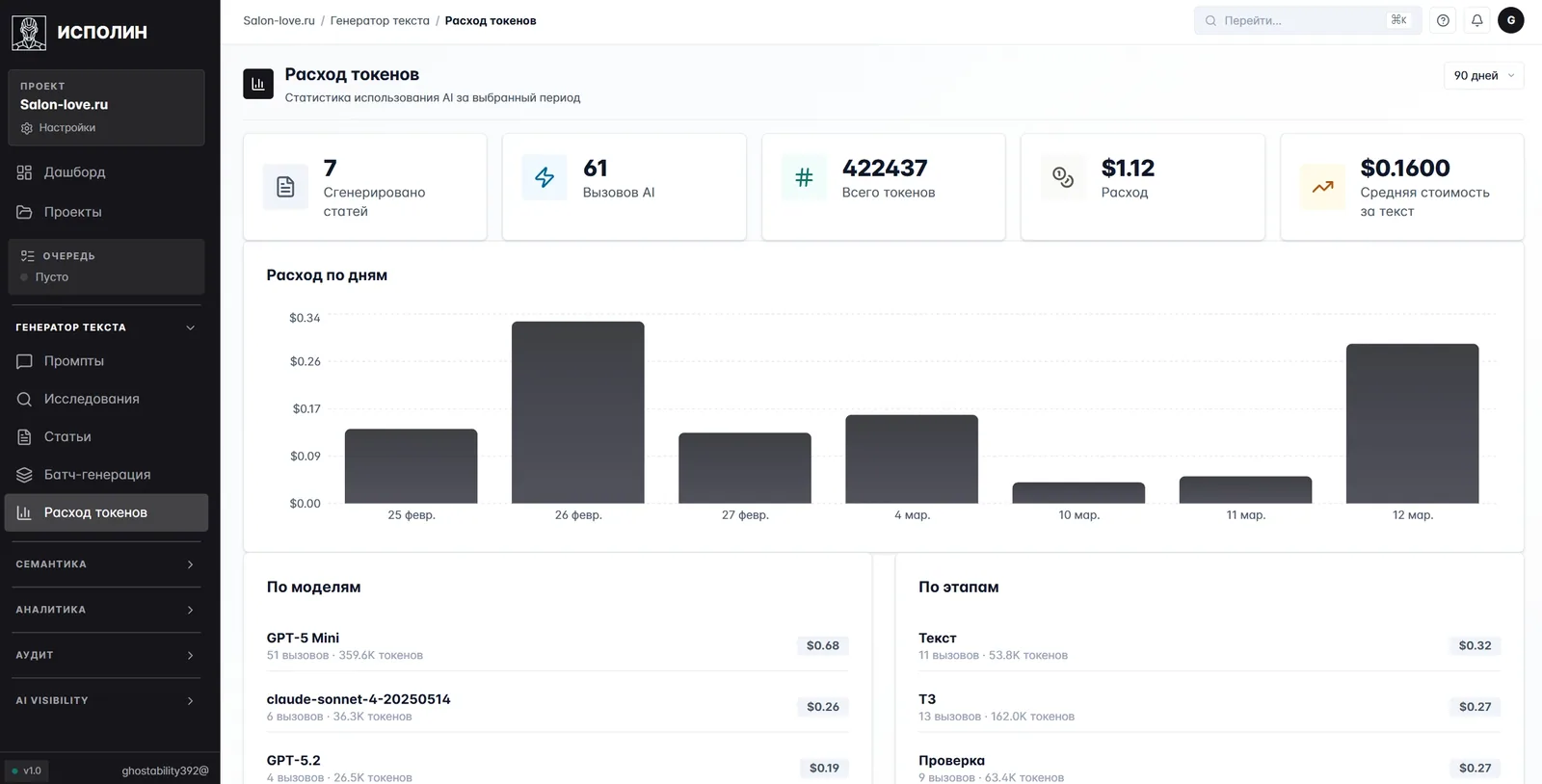
Контроль расходов на AI — отдельный экран с тремя разрезами одновременно. График по дням показывает, куда уходили токены за квартал. Слева внизу — по моделям: GPT-5 Mini за 90 дней обошёлся в 68 центов, GPT-5.2 — 19 центов, claude-sonnet-4 — 26 центов. Справа внизу — по этапам пайплайна: Текст 32 цента, ТЗ 27, Проверка 27. Средняя цена статьи — 16 центов, или примерно 13 рублей по курсу 80.
Промпт-слой удерживает стиль проекта на потоке. Расходный экран показывает цену каждой статьи в любой момент. Скрытых счетов и абонентских плат за безлимит у нас нет.
Что выходит на руки клиенту
После месяца работы у клиента есть четыре актива.
Размеченное семантическое ядро — живая структура с кластерами, скорингом, частотами и приоритетами. К ней привязаны все остальные данные платформы.
Поток статей, прошедших исследование конкурентов, AI-генерацию по ТЗ, AI-проверку и редакторскую вычитку. На крупном проекте уходит десятки готовых статей в неделю.
Аналитика на одном экране: трафик, позиции, прогноз и работы команды за период. Плюс прогноз на год через ансамбль моделей — отдельный аналитик потратил бы на такое целый рабочий день.
Цифра видимости в AI. Видно, цитируют нас в Алисе и ChatGPT или нет, и куда движется тренд. Метрика молодая, в индустрии её мало кто меряет — поэтому она стоит рядом с трафиком и позициями уже сейчас, пока конкуренты считают только классическую выдачу.
Что в следующих статьях
Прошёлся по платформе обзорно. Каждый модуль — отдельная большая тема. Про семантику с её четырьмя источниками расширения, контент-пайплайн с проверкой моделью, прогноз трафика на ансамбле моделей, GEO-аудит и мониторинг видимости в LLM ещё будут отдельные разборы с реальными цифрами и кейсами.
Если хочется развернуть ИСПОЛИН под свою команду — пилот занимает примерно две недели. За это время мы ставим платформу на ваших серверах, переносим действующие проекты, настраиваем промпты под стиль ваших текстов и обучаем команду. За каждый модуль — единоразовый платёж, без подписок. На руки получаете рабочую инсталляцию и полный админский доступ. Подробности — на странице платформы.
Хотите развернуть ИСПОЛИН под вашу команду
Платформа разворачивается под ключ для агентств и in-house SEO-команд. Перенос текущих проектов, настройка промптов под стиль ваших текстов, обучение команды на пилотном клиенте.
Перейти на страницу платформы — ispolin.pro/platform →


