
Каждый третий запрос — без перехода
Алиса AI отвечает на 36% запросов в Яндексе прямо в выдаче. Так теперь устроен Яндекс: пользователь читает ответ, видит источники, закрывает страницу. Перехода на сайт нет.
Это меняет всё. Семнадцать лет SEO-индустрия мерила одну вещь — позицию страницы в выдаче и трафик с этой позиции. Сегодня треть аудитории не доходит до позиции вообще: вопрос задан, ответ получен, диалог закрыт. Сайт остался невидимым для пользователя, хотя именно с него Алиса собрала факты.
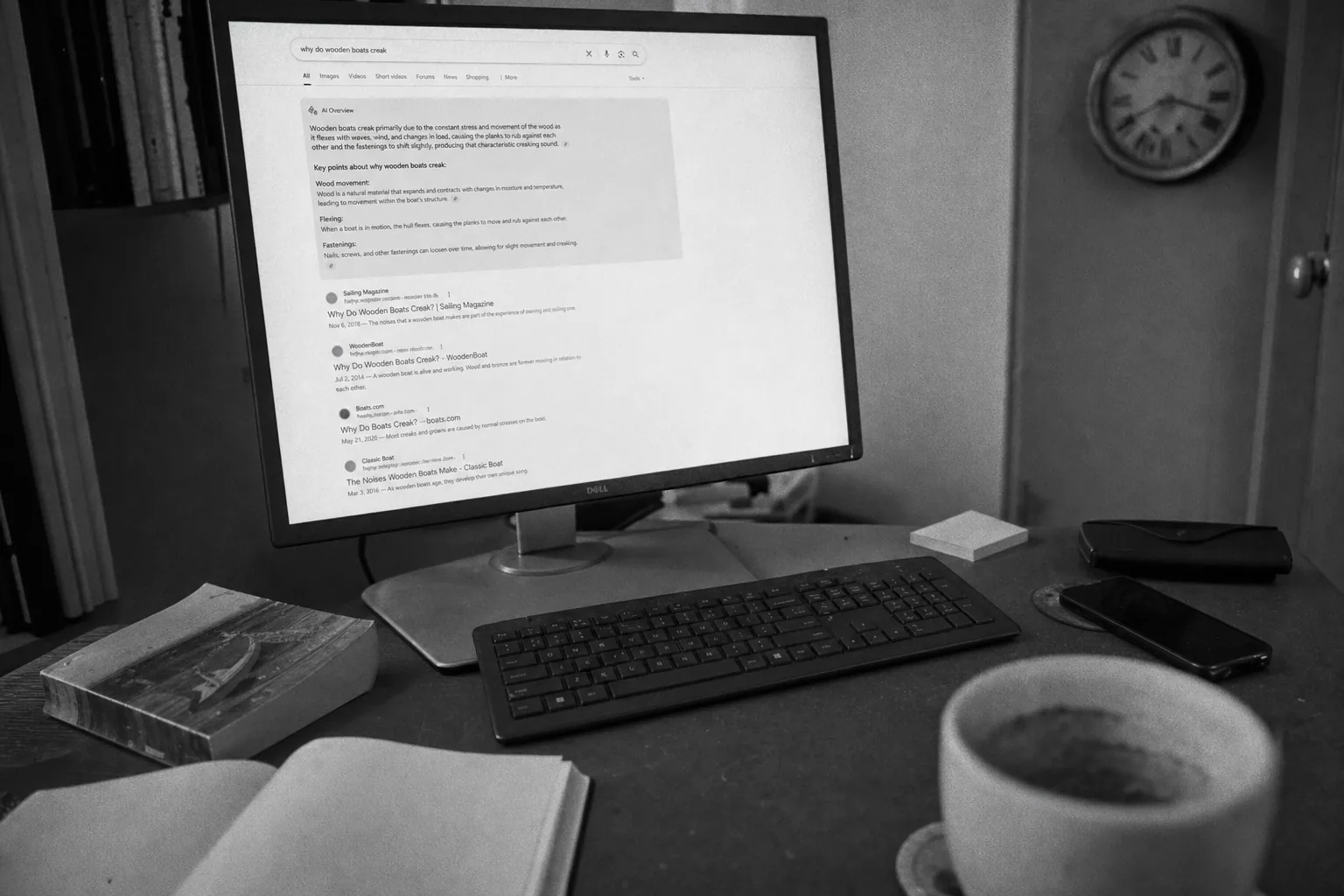
Здесь и появляется GEO. Generative Engine Optimization — новый слой работ, который отвечает на простой вопрос: какие ваши страницы цитируют AI-движки и почему? И, отдельный вопрос, — а они вас вообще читают?
SEO-аудиты сломались о AI-поиск
Старая схема аудита упирается в три вещи: что в индексе, какая позиция, какая скорость. Дальше — большая папка рекомендаций по тегам и ссылкам.
С приходом Алисы AI, ChatGPT, Perplexity и GigaChat этот набор перестал покрывать задачу. AI-движок не ставит позицию в выдаче — он либо процитировал ваш блок, либо нет. Не выводит вас на первой странице — выводит цельный ответ из нескольких источников. Не учитывает ссылочный профиль так, как учитывает Яндекс — оценивает доверие к домену по совершенно другим сигналам.
Итог: классический аудит говорит «у вас всё хорошо», а доля цитирования бренда в Алисе — 0%. Эти две картины перестали совпадать в 2024–2025 годах. К 2026-му разрыв стал слишком большим, чтобы его игнорировать.
Российский AI-поиск — отдельный
В рунете рынок AI-поиска делят четыре движка, и каждый тащит цитаты по своим правилам.
Алиса AI и Яндекс Нейро. Главный игрок на российском рынке, около трети запросов в Яндексе. Завязан на индекс Яндекса — если вас не индексирует Яндекс, в Алисе вас тоже не будет. Любит свою связку Schema.org, корректный sameAs до представительств в VK и Дзене, региональную привязку.
ChatGPT Search. Глобальный игрок с самой широкой обучающей базой. Цитирует охотно, но избирательно: предпочитает структурированные определения и числа. Хорошо относится к спискам с конкретикой и плохо — к воде.
Perplexity. Поисковик с явными цитатами: каждая фраза в ответе сопровождается ссылкой на источник. Здесь критична позиция в SERP, наличие схема-разметки и доступ для PerplexityBot в robots.txt. Если бот закрыт, вас не будет в источниках.
Claude и Gemini. Аккуратнее с источниками, ценят авторитетность площадки. Лучше всего работают с длинными аналитическими статьями, где есть биография автора и проверяемые факты.
Оптимизация под один движок не покрывает остальные. Контент, который Алиса цитирует охотно, ChatGPT может вообще не заметить — у них разные сигналы и разные правила.
Появилась инфраструктура, которой раньше не было
Под цитирование в LLM выросло отдельное техническое окружение. Если этих компонентов на сайте нет, AI-движкам нечего цитировать — они идут к конкурентам, у которых это есть.
Всего три уровня:
- Машинная читаемость. llms.txt, JSON-LD, чистая семантическая разметка. Корм для модели в том виде, в котором она его понимает.
- Доступ для ботов. robots.txt с разрешениями для GPTBot, ClaudeBot, PerplexityBot и ещё пары десятков. Многие сайты по умолчанию закрывают всех — и потом удивляются, что не цитируются.
- Связь с миром. sameAs-разметка с привязкой к Wikipedia, VC.ru, YouTube-каналам, Telegram. Бренд для модели становится сущностью только когда о нём говорят в нескольких местах согласованно.
Все три уровня появились за последние два года. В стандартный чек-лист SEO-аудита они ещё не попали.
Хотите посмотреть, как ваш сайт устроен по этим трём уровням
GEO-аудит ИСПОЛИНа смотрит на сайт глазами AI-движка: что видит GPTBot, какая разметка работает, какие площадки знают ваш бренд. Десять независимых рубрик, композитный скор 0–100, отчёт с конкретными правками.
Посмотреть состав услуги — ispolin.pro/geo-services →
Сайт — не мешок страниц
Это главная мысль методики. Прежде чем писать рекомендации, мы делим сайт на три зоны и судим каждую по её собственным критериям.
Коммерческая зона. Главная, каталог, карточки товаров, страницы услуг, лендинги. Страницы, которые непосредственно зарабатывают. Цель — продажа через SEO. Метрики — конверсия и позиция в выдаче.
Редакционная зона. Блог, гайды, FAQ, экспертные разборы. Не продаёт напрямую, но снимает возражения и кормит AI-движки. Цель — цитируемость в AI. Метрика — упоминания в ответах LLM.
Фундамент. О компании, команда, контакты, политика, представительства. Страницы, которые подтверждают: бренд реальный. Цель — доверие и E-E-A-T. Метрики — связки sameAs, упоминания на сторонних площадках.

У каждой зоны свой язык и свои типичные провалы. Главное правило: критерии одной зоны нельзя переносить на другую. И вот тут возникает самая частая и самая разрушительная ошибка GEO-оптимизации.
Ловушка «Платье — это предмет одежды»
Команда читает гайд по GEO. В гайде написано: «AI цитирует самодостаточные абзацы, начинайте страницы с определений». Команда идёт переписывать всё подряд, включая каталог.
Что получается на странице каталога платьев:
«Платье представляет собой одно из старейших видов одежды человечества. Существуют различные стили платьев, отличающиеся длиной, кроем и материалом изготовления...»
Время на странице — растёт. Конверсия — падает. AI-движок не цитирует, потому что не находит факта. Поисковик понижает позицию, потому что страница не отвечает на коммерческий интент: пользователь искал «купить платье», а получил статью энциклопедии.
Что должно быть на той же странице:
«Каталог платьев на сезон весна 2026: 142 модели, 5 брендов, цены от 3 800 до 24 000 ₽. Доставка по РФ за 1–3 дня, примерка 7 дней. В наличии в Москве и СПб.»
Конкретные цены, числа, бренды, география. AI-движок цитирует — есть, что цитировать. Поисковик ранжирует выше — интент совпадает.
Совет «начинайте страницу с определения» работает только в редакционной зоне. В коммерческой он убивает страницу. В фундаменте он просто бесполезен — там нужны имена, адреса, ИНН и реквизиты.
Аудит начинается с распознавания
Без профиля проекта любая проверка — выстрел вслепую. Для интернет-магазина платьев и для медиа про моду критерии будут совершенно разные, хотя домен у них один и тот же.
Профиль состоит из четырёх параметров:
- Бизнес-тип. В нашей классификации — одиннадцать категорий: e-commerce, услуги для частных, услуги для бизнеса, SaaS, медиа, образование, финансы, медицина, HoReCa и туризм, недвижимость, личный бренд. От бизнес-типа зависит, какие зоны должны быть на сайте и какие платформы важны для распознавания бренда.
- Бренд. Имя, источники упоминаний, факт распознавания моделью. Опознать бренд для AI — не то же самое, что зарегистрировать торговую марку. Это вопрос, видит ли LLM ваше название как сущность с признаками.
- Стек. На какой CMS сделан сайт, какие фреймворки. Стек определяет половину технических проблем: серверный рендер или клиентский, заголовки безопасности, заголовки кеширования, контроль за robots.txt.
- Структура сайта. Шаблоны URL и распределение типов страниц. Какие страницы у вас есть, какие отсутствуют, как они между собой связаны.
Только после профилирования начинается собственно аудит. Иначе мы попадаем в ситуацию, когда стоматологии советуют завести каталог товаров, а интернет-магазину — добавить раздел «авторские мнения». Чек-листы из YouTube-роликов часто грешат именно этим.
Как опознать бренд для машины
LLM не доверяет сайту, про который снаружи никто не пишет. Чтобы бренд для машины стал сущностью, нужны явные сигналы. Их мы тащим из четырёх независимых источников.
Wikipedia. Поиск страницы по названию бренда плюс фильтр по токенам — отсекаем омонимы. Если статьи нет, это не катастрофа; если есть — модель почти наверняка знает бренд.
Реестр платформ по бизнес-типу. Около тридцати двух авторитетных площадок, разбитых по нишам: для e-commerce — одни, для медицины — другие, для SaaS — третьи. Проверяем наличие профиля и заполненность.
Schema.org sameAs. Связки с собственными представительствами в соцсетях, на YouTube, в Telegram, в Дзене. Машинно-читаемый ярлык «вот этот аккаунт — это мы».
SERP Яндекса по брендовому запросу. Что поисковик показывает в выдаче на ваш бренд. Какие сторонние сайты говорят о вас, какие — оспаривают, каких упоминаний нет вообще.
Четыре источника независимы. Если три из них пустые, никакой llms.txt не спасёт — модель просто не видит бренд как сущность.
У каждой страницы свой тип и свои критерии
Прежде чем оценивать, аудит относит каждую страницу к одному из десяти типов: главная, каталог, карточка товара, услуга, посадочная, статья, гайд, FAQ, страница «О компании», контакты. Дальше критерии берутся под тип.
Главную мы судим по полноте бренд-блока и наличию навигации к ключевым зонам. Карточку товара — по цене, остатку, доставке, отзывам. Статью — по структуре, биографии автора, дате обновления, фактическому материалу. FAQ — по чёткости пары «вопрос-ответ» и наличию FAQPage-разметки.
Если перепутать критерии, аудит превращается в шум. Карточку товара по критериям статьи завалит любая. Статью по критериям карточки — точно так же. Эта простая мысль не везде проговорена в индустрии, и из-за неё рождаются типовые «универсальные» рекомендации, которые ломают сайты больше, чем чинят.
Сначала сигналы, потом суждения
Сигналы извлекаются один раз. HTTP-ответы, заголовки, наличие Schema.org, цены, заголовки H1–H3, авторы статей, даты публикации, robots.txt, sitemap.xml, llms.txt. Получили факты по сайту.
Дальше этими фактами пользуются все десять рубрик аудита. Коммерческая рубрика смотрит на цены, CTA, категории. Редакционная — на факты, авторов, даты. Фундамент — на контактные данные и sameAs. Технический слой — на llms.txt и schema. Стратегический — на структуру сайта в целом.
Один раз собрали — десять раз использовали. Так получаем воспроизводимость: аудит, прогнанный сегодня и через неделю по тому же сайту, даёт сопоставимые цифры. Если каждая рубрика сама по себе ходит по сайту и собирает свои данные, получится десять разных картин и сравнить их между собой нельзя.
Часть проверок имеет смысл только на уровне всего сайта — robots, sitemap, заголовки безопасности, наличие блога, наличие /about. Другая часть привязана к отдельной странице — цитируемость, разметка, соответствие типу. Эти слои держим отдельно и считаем независимо.
Десять рубрик и композитный скор
В нашей методике аудит складывается из десяти независимых рубрик. На средний сайт (300–500 страниц в выборке) уходит около 24 часов работы аналитика. Каждая рубрика отвечает на одну ясную задачу. Слои между собой не пересекаются.
- Цитируемость. Берём пять самых важных блоков на странице, оцениваем каждый по четырём осям и возвращаем три лучших на усиление и три худших на переписывание.
- E-E-A-T. Опыт, экспертиза, авторитет, надёжность — четыре измерения от годов на рынке до реквизитов.
- Авторитет бренда. Wikipedia, YouTube, VC.ru, Habr, Дзен, Telegram, VK — семь платформ, откуда LLM узнают про бренды.
- JSON-LD и sameAs. Одиннадцать типов Schema.org для разных страниц.
- Технический слой. Core Web Vitals, серверный рендер, HTTPS, заголовки безопасности, robots.txt, sitemap.xml.
- Видимость без JavaScript. Загрузка глазами GPTBot против браузера. Процент контента, которого AI просто не видит.
- Реестр AI-ботов 2026. Девятнадцать ботов с делением по ролям. Блокируем только тех, кто обучает модели.
- llms.txt. Проверка или создание по стандарту Джереми Хауарда. Разделы: каталог, услуги, блог.
- Стратегическое покрытие. Наличие блога, наличие /about, наличие /contacts. Чего на сайте принципиально не хватает.
- Видимость в LLM. Опрос Алисы Нейро, ChatGPT и GigaChat по 20–150 промптам. Доля упоминаний, позиция, доля бренда.
Каждая рубрика даёт свой балл. Десять баллов складываются в композитный скор от 0 до 100. Скор нужен не для красоты — он нужен для объективной дельты между замерами. После каждой итерации видно, что сдвинулось, в какой рубрике, на сколько.
Заказать прогон сайта по этим десяти рубрикам
Около 24 часов работы аналитика на средний сайт, отчёт с разбивкой по каждой рубрике и списком приоритетных правок. Дальше — две недели на доработки и повторный замер для дельты.
Оставить заявку — ispolin.pro/geo-services →
Цитируемость: пять блоков по сто пятьдесят слов
Главная рубрика для редакционной зоны и самая трудоёмкая. Логика такая.
На каждой статье берём пять самых важных смысловых блоков по 100–200 слов. Размер взят не случайно — это типичный размер цитаты, который AI-движок выдёргивает в ответ. Меньше — нет контекста; больше — модель порежет и потеряет суть.
Каждый блок оцениваем по четырём осям:
- Самодостаточность. Понятен ли блок без остальной статьи? Если для понимания нужны соседние параграфы — модель его не процитирует.
- Фактическая плотность. Сколько чисел, имён, дат, конкретных параметров на единицу текста.
- Структурность. Ясен ли заголовок блока, есть ли явный логический ход.
- Авторская позиция. Видно ли мнение, отличающееся от усреднённого, или это пересказ Wikipedia.
В отчёте отдаём три лучших блока с пометкой «усилить и тиражировать» и три худших — «переписать или удалить». Без этой рубрики разговор про оптимизацию под AI становится пустым: команда соглашается, что «надо писать лучше», и расходится.
Четыре измерения E-E-A-T
E-E-A-T — рамка Google: Experience, Expertise, Authoritativeness, Trustworthiness. AI-движки используют похожие сигналы, чтобы решить, можно ли вам доверять. Меряем все четыре измерения отдельно.
Опыт. Годы на рынке, количество реализованных проектов, конкретные кейсы с цифрами. Сюда же — фотографии команды, фотографии офиса, видео изнутри.
Экспертиза. Биографии авторов, образование, публикации в отраслевых изданиях, выступления на конференциях. Если статью пишет аноним без биографии — экспертиза равна нулю в глазах модели.
Авторитет. Упоминания на сторонних площадках, ссылочный профиль, Wikipedia, отзывы в каталогах. Бренд авторитетен тогда, когда о нём говорят другие.
Надёжность. Реквизиты, политика возврата, сертификаты, физический адрес, телефон с реальным региональным кодом. Базовая чистота, которую модель проверяет молча.
Четыре измерения дают независимые баллы. Сайт может проседать в одном измерении и тащить ситуацию остальными — например, у молодого SaaS мало опыта, но сильная экспертиза за счёт авторов. Это видно по разбивке.
Семь платформ для бренда
Один сайт LLM не учит. Бренд становится знакомым, когда о нём говорят в семи разных местах согласованно. Семь платформ — наблюдаемый минимум для устойчивого распознавания в рунете.
- Wikipedia. Базовая статья хотя бы в один абзац.
- YouTube. Канал бренда или экспертные интервью основателей.
- VC.ru. Кейсы, аналитика, авторские колонки.
- Habr. Технический контент, если бизнес связан с технологиями.
- Дзен. Длинная редакционная аналитика для русскоязычной аудитории.
- Telegram. Канал бренда с регулярными постами.
- VK. Сообщество с описанием, фотографиями, контактами.
Все семь связываем sameAs-разметкой. Это ярлык для модели: «вот этот VK-аккаунт — наш, вот этот Telegram — наш, вот этот Дзен — наш». Без sameAs модель видит семь разрозненных аккаунтов с похожими названиями и не уверена, что они принадлежат одной сущности.

Заполненность всех семи площадок проверяет отдельная рубрика аудита. Карта дыр — что заведено и работает, что заведено и заброшено, чего нет вовсе.
JSON-LD: инструкция для модели прямым текстом
JSON-LD — это инструкция для LLM прямым текстом: «вот эта страница про продукт, цена такая, организация — вот эта». Без неё машине приходится догадываться по тегам и тексту, и она ошибается.
Одиннадцать типов Schema.org покрывают большинство сценариев в рунете:
- Organization — базовый объект бренда.
- LocalBusiness — адрес, часы, координаты для бизнеса с физической точкой.
- Article — автор, дата, headline.
- Product — цена, валюта, наличие.
- FAQPage — пара «вопрос-ответ» специально для AI.
- BreadcrumbList — иерархия страницы в структуре сайта.
- Person — автор с биографией.
- Service — услуга, цена, область применения.
- Review / AggregateRating — отзывы и средний балл.
- HowTo — пошаговая инструкция.
- Event — дата, место, билеты.
Аудит проверяет наличие нужного типа на каждом типе страниц и валидность разметки через парсер. Невалидная разметка для модели хуже, чем её отсутствие — модель видит сигнал и принимает решение по нему, а сигнал кривой.
Что видит GPTBot, когда сайт у него в зубах
GPTBot, ClaudeBot, PerplexityBot не запускают JavaScript. Они получают тот HTML, который сервер отдал в первом ответе — и ничего больше. Если каталог, отзывы и блог рендерятся клиентом, для AI сайта нет.
Меряем это методом двойного запроса: сначала загружаем страницу глазами GPTBot (User-Agent: GPTBot/1.2, plain fetch без браузера), потом полноценно через headless-браузер. Сравниваем DOM. Получаем процент невидимого контента и конкретные блоки, которые модель не увидит.
Типичная картина в 2026 году: коммерческие сайты на популярных JS-фреймворках теряют для AI 40–70% контента. Карточки товаров рендерятся клиентом, отзывы загружаются динамически, блог открывается через React-роутер. Серверный рендер исправляет это в большинстве случаев — но включить его на проекте, где этого никогда не было, может быть отдельной задачей на пару спринтов.
В отчёте отдаём процент невидимого + список конкретных блоков, которые AI не получает. С таким списком разработчик чинит проблему точечно, а не идёт переписывать весь фронтенд.
Девятнадцать AI-ботов и их роли
Самая частая ошибка клиента — закрыть всё через User-agent: * в robots.txt. Логика «не пускать никаких роботов» когда-то работала против скрапинга, сейчас она ломает AI-видимость на корню.
Боты делятся по ролям:
- Тренируют модели. GPTBot, ClaudeBot, Bytespider, Google-Extended. Их можно блокировать, если вы не хотите, чтобы ваш контент попал в обучающие выборки. Это политическое решение, а не техническое.
- Индексируют для поиска. OAI-SearchBot, ChatGPT-User, PerplexityBot. Этих блокировать нельзя — без них вас не будет в ответах AI-поисковиков. Большинство сайтов закрывает их случайно, заодно с тренировочными.
- Тянут страницу по запросу. Anthropic-User, Perplexity-User, Bingbot. Загружают страницу в момент, когда пользователь задал вопрос. Тоже нужны.
Bytespider от ByteDance — отдельный случай. Скачивает агрессивно, тренирует Doubao, в ответы российских AI-поисковиков не приносит ничего полезного. Большинство клиентов его блокируют.
В отчёте — текущая конфигурация robots.txt и список ботов с пометкой «оставить открытым», «закрыть», «решение клиента».
llms.txt: стандарт Джереми Хауарда
llms.txt — текстовый файл в корне сайта, который описывает важнейшие разделы человекочитаемым образом. Стандарт предложил Джереми Хауард (бывший fast.ai) в 2024 году. К 2026-му он стал де-факто стандартом, который читают все основные AI-движки.
Структура простая: заголовок сайта, описание, ссылки на ключевые разделы с короткими аннотациями. Каталог, услуги, блог, FAQ, контакты — каждое со своей секцией.
Аудит либо проверяет существующий файл на полноту, либо собирает черновик с нуля по структуре сайта. Полноту проверяем по нескольким признакам: покрыты ли все ключевые разделы, актуальны ли URL, описаны ли страницы понятным языком (а не списком технических заголовков).
Важно: llms.txt — это последний пункт инфраструктурной готовности, а не первый. Сначала разбираемся с зонами, типами страниц, разметкой, доступом ботов. Потом, когда инфраструктура сложилась, llms.txt подытоживает её для модели. Иначе вы получаете аккуратный файлик, описывающий бардак.
AISVS — индекс видимости в AI-выдаче
Восемь технических рубрик отвечают, готов ли сайт к AI-цитированию. Но сам факт цитирования живёт не на сайте, а в ответах Алисы Нейро, ChatGPT и GigaChat. Чтобы это измерить, надо опросить движки напрямую.
Корзина из 20–150 промптов под бренд и его темы, прогон через три AI-движка, повторный прогон через две недели. Стоимость одного прогона — около 30 ₽ на трёх движках. Делаем дважды в месяц для динамики.
AI Search Visibility Score (AISVS) — отраслевая метрика 2026 года. Считает четыре независимых сигнала и складывает с весами:
- Citation Rate (35%). Доля промптов, в ответах на которые упомянут бренд.
- Position Score (25%). На каком месте в ответе бренд упомянут — первым, в середине, в конце.
- Answer Share (25%). Доля токенов бренда от общего объёма ответа. Грубо: насколько большой кусок ответа посвящён вам.
- Persistence (15%). Устойчивость во времени. Если в одном замере упомянуты, а через две недели — нет, метрика падает.
На выходе один балл от 0 до 100 и понятная декомпозиция: что именно тянет вниз. Дальше работа точечная: проседает Position Score — улучшаем сигналы цитируемости на конкретных страницах; проседает Persistence — добавляем регулярную публикационную активность и упоминания на платформах.
Шесть мифов, которые слышим чаще всего
Если один из них живёт у вас в команде, дальше можно не оптимизировать ничего: бюджет уйдёт на «правильное» SEO, а доля цитирования останется нулевой.
«AI-поиск — нишевая история, основной трафик из Яндекса». Яндекс сам закрывает 36% запросов Алисой AI. Классический поиск Яндекса теперь так и работает.
«Нельзя гарантировать попадание в ответы ChatGPT и Perplexity». Гарантируем сигналы, которые LLM считывает: citability-структуру, JSON-LD, sameAs, llms.txt, E-E-A-T. Позиций никто не обещает. Сигналы дают вероятность резко выше нуля.
«Это просто перепакованное SEO под новым именем». SEO считает TF-IDF и ссылочный вес. GEO считает извлекаемость самодостаточного блока и узнаваемость бренда как сущности. Аудит на десять категорий отличается от SEO-аудита полностью.
«Как измерить результат, если ответы AI не стабильны?». Композитный скор 0–100 по десяти осям, мониторинг цитируемости через AISVS, трекинг упоминаний бренда по семи источникам. Дельта между замерами объективна, даже когда отдельные ответы AI шумят.
«Моя ниша слишком узкая, чтобы AI о ней знал». Алиса AI отвечает и на коммерческие запросы — «купить», «цена», «где заказать». Узкая ниша — плюс: ниже конкуренция за место источника.
«Дорого и долго — проще нагнать контекстной рекламы». GEO — накопительный канал. llms.txt, sameAs и citability работают годами без рекламного бюджета. Реклама останавливается в день отключения.
Чего GEO-аудит не делает
Честный список того, что наш аудит явно не обещает. Эти границы стоит проговорить заранее.
Гарантию места в ответе AI. Модели вероятностные. Гарантировать конкретный ответ на конкретный промпт нельзя ни в одной методике. Можно поднять вероятность с нуля до устойчивых 30–60% — и это уже совсем другая ситуация.
Замены ссылочного продвижения. Авторитет бренда строится в том числе через ссылочный профиль. GEO-аудит говорит, какие площадки нужны для упоминаний; добиваться этих упоминаний — отдельная работа PR и линкбилдинга.
Замены контекстной рекламы и performance-каналов. GEO работает на горизонте кварталов и лет, реклама — здесь и сейчас. Это разные инструменты для разных задач.
Замены продакта. Если у сайта плохая конверсия из-за слабого продукта или неудобной формы — это не лечится разметкой. Аудит честно говорит «здесь конверсия проседает по продуктовым причинам, GEO не поможет».
Не начинайте с llms.txt
Главная мысль, которая стоит унести из всего разговора. Большинство команд, услышав про GEO, идут гуглить «как сделать llms.txt» и пишут файл за час. Это худшая последовательность шагов из возможных.
Начните с вопроса — в какой зоне ваш сайт и что у этой зоны за работа. Иначе вы оптимизируете главную под цитирование и убиваете её как продающую. Это происходит постоянно: команда читает гайд по GEO, берёт продуктовую страницу и переписывает её как статью энциклопедии. Конверсия падает, цитируемость не растёт. Через два месяца компания приходит за аудитом и слышит, что чинить пришлось то, что недавно сами же и сломали.
GEO — не магия и не волшебная разметка. Это переосмысленная карта сайта, в которой каждой странице вернули её собственную работу, а инфраструктура (доступ для ботов, разметка, llms.txt) надстроена поверх правильной карты, а не вместо неё.
Десять рубрик аудита, композитный скор, AISVS — рабочие инструменты, чтобы эту карту нарисовать и удерживать в актуальном состоянии. Без них любой разговор про оптимизацию под AI быстро вырождается в споры на уровне «надо писать лучше». А «лучше» — это понятие, которое каждый понимает по-своему.
Прогнать ваш сайт по этой методике
Всё, что разобрано в статье, — рабочая услуга ИСПОЛИНа. Технический слой, контент, бренд, фундамент. Композитный скор 0–100, отчёт с правками для маркетинга, разработки и контент-команды, мониторинг цитируемости в Алисе Нейро и ChatGPT.
Перейти на страницу GEO-услуг — ispolin.pro/geo-services →


